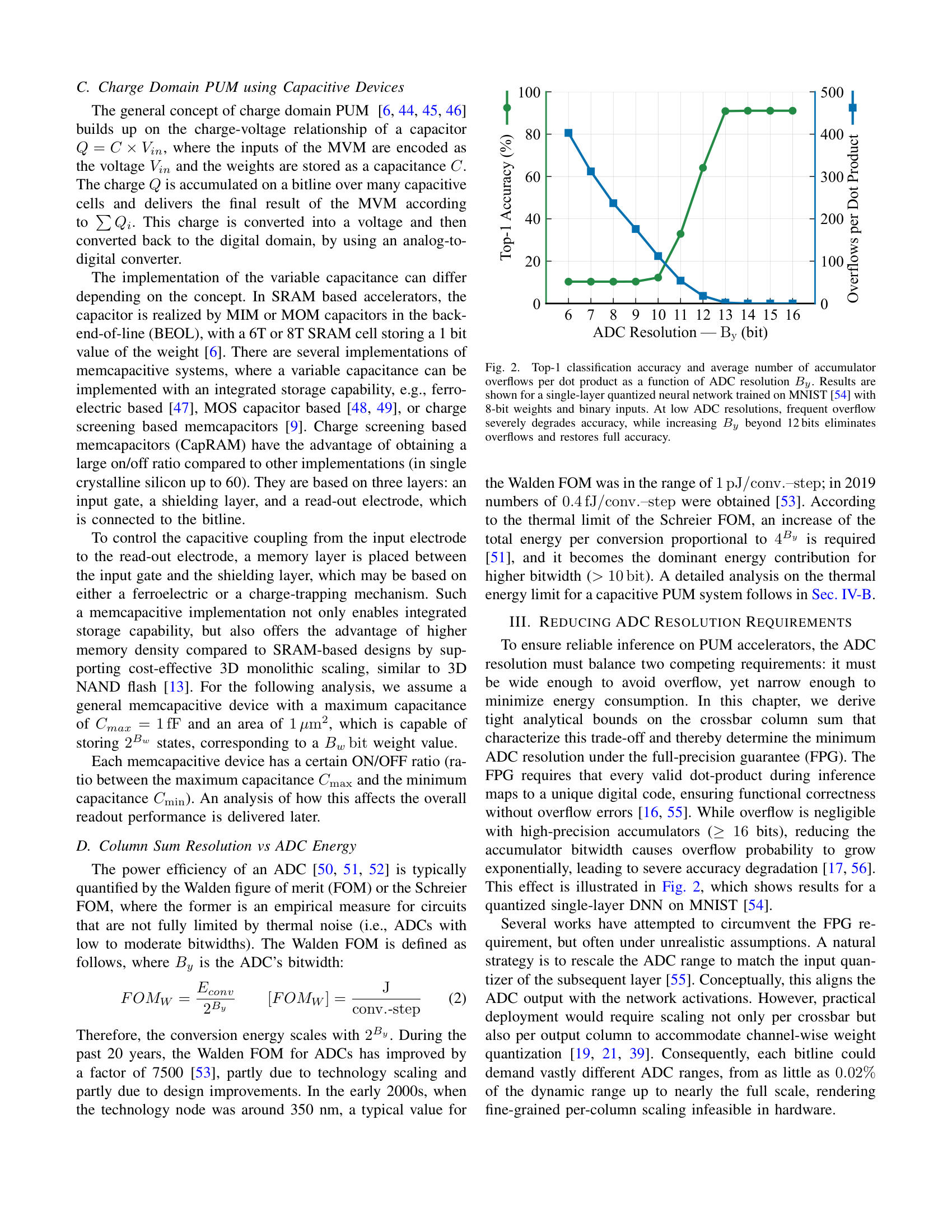
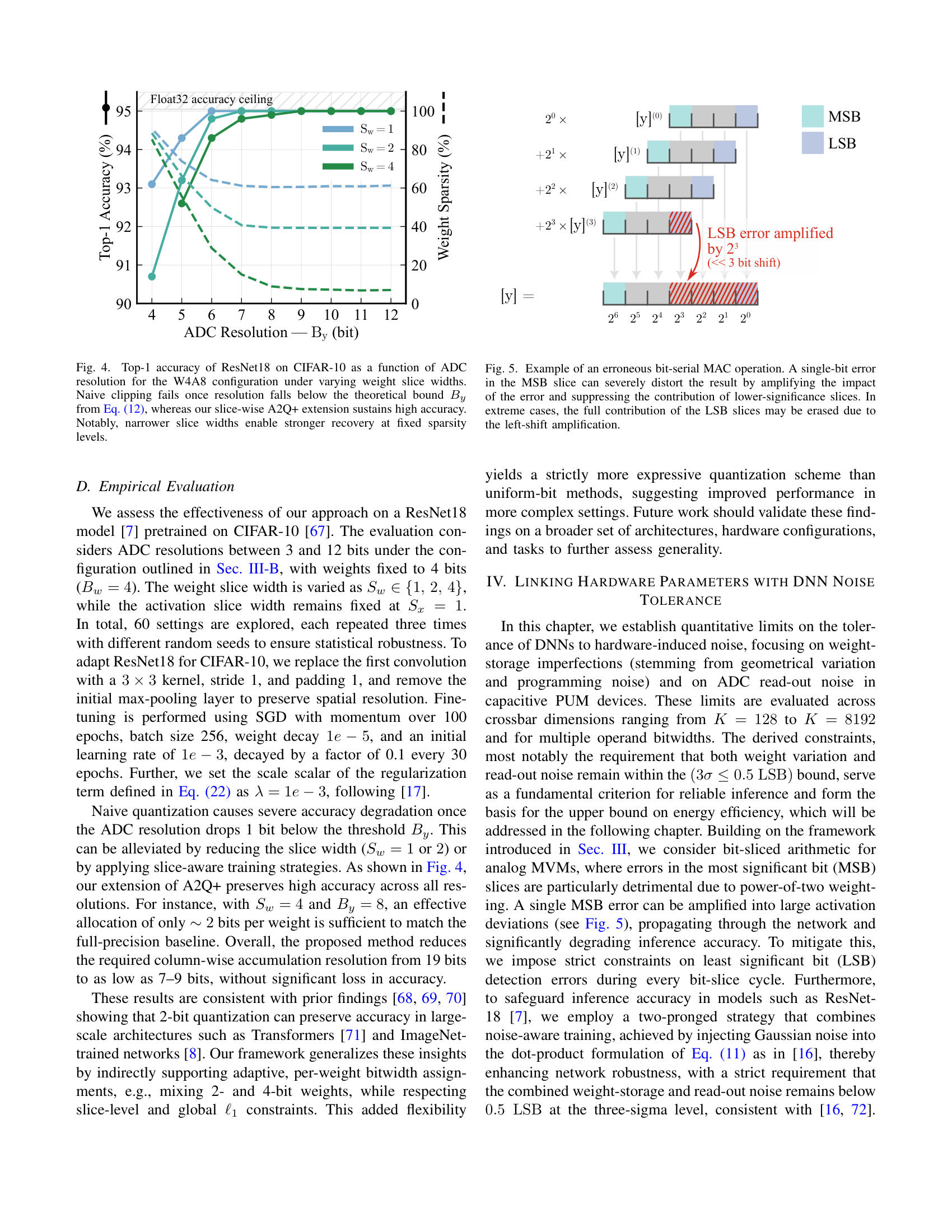
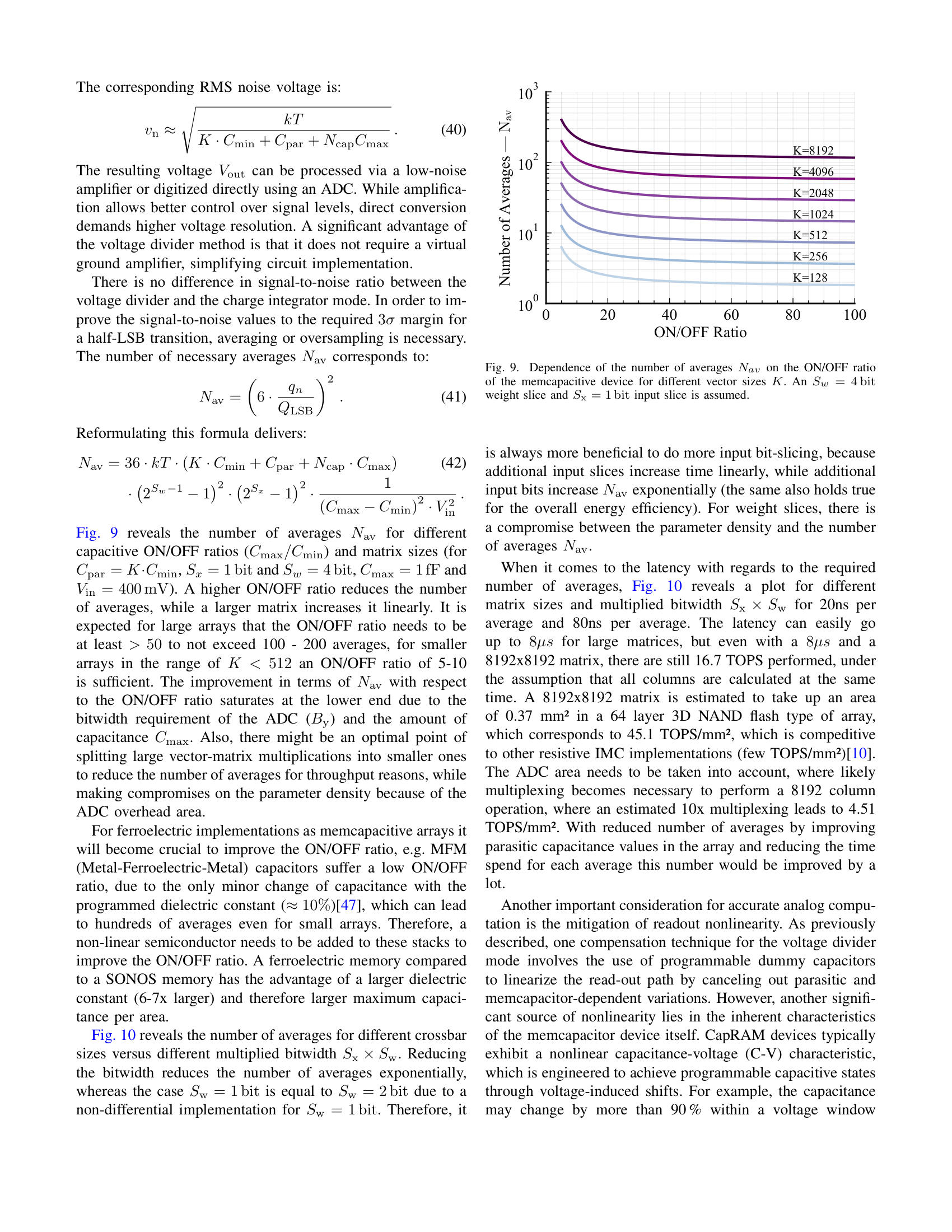
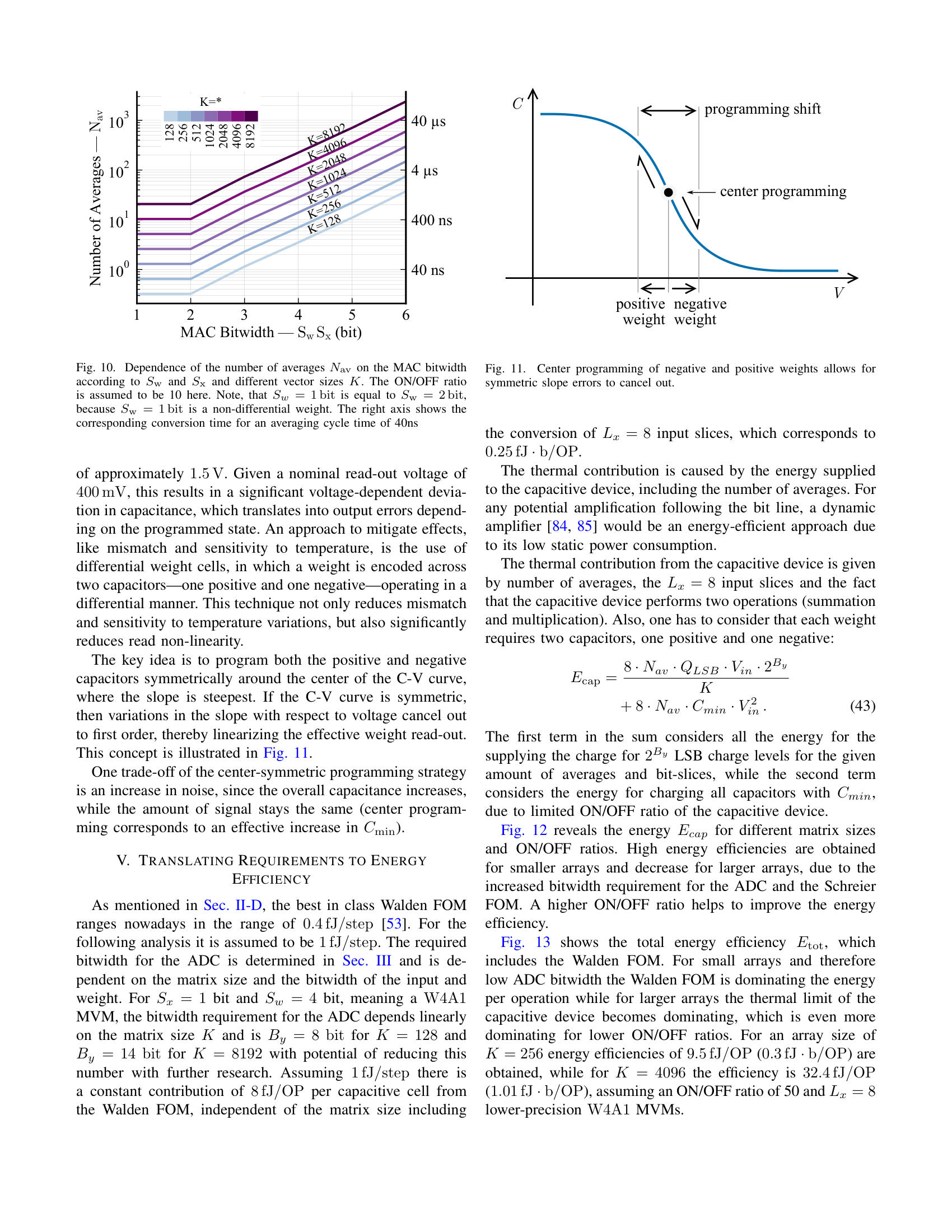
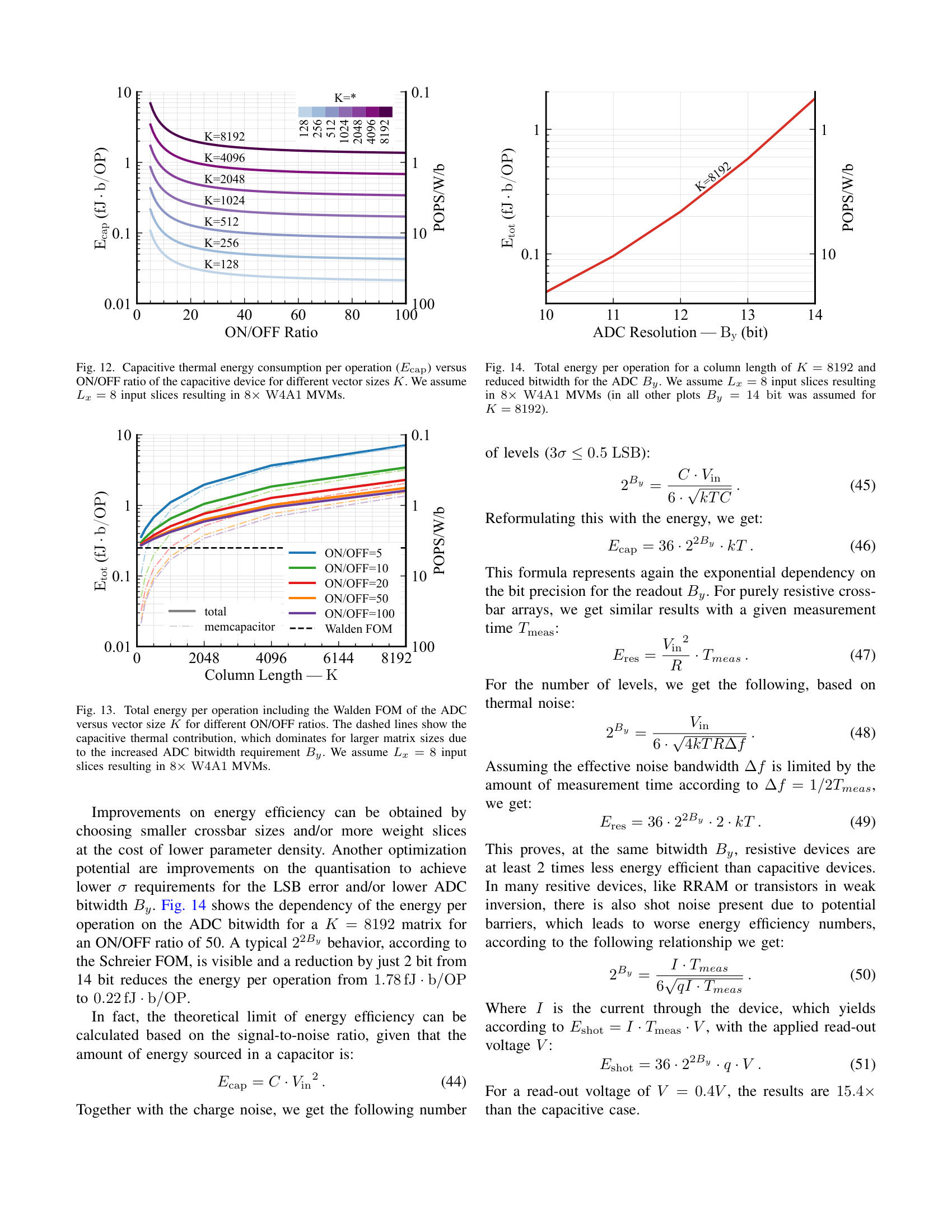
A Blueprint for Accurate, Energy-Efficient DNN Inference via Capacitive In-Memory Processing 2025-10-08 — Kai-Uwe Demasius, Alexander Lowa, Boris Murmann, SEMRON Introducing the trade-offs and challenges for Capacitive In-Memory Processing, from the manufacturing to the software level 📥 Download PDF ⬇ 📖 Published version ↗ This paper was presented at the CCMCC 2025 in Dresden. ABlueprintforAccurate,Energy-EfficientDNNInferenceviaCapacitiveIn-MemoryProcessing Kai-UweDemasius 1 AlexanderLowa 1 BorisMurmann 21 SEMRON,Dresden,Germany 2 UniversityofHawaiiatManoa,Hawaii,USA Abstract —Thispaperpresentsahardware–softwareco-designmethodologyforaccurateandenergy-efficientDNNinferenceoncapacitiveprocessing-using-memory(PUM)systems.Wein-vestigatethefundamentalalgorithm–hardwareinteractionsthatlimitanalogaccelerators,focusingonaccumulatorresolutionandnoiseresilience.Toeliminateimpracticalrequirementsforperipheralcircuitry,weintroduceaprecision-awaretrainingframeworkthatminimizestheeffectiveresolutionofADCsandenhancesrobustnesstocircuit-levelnon-idealitiessuchasdevicevariabilityandread-outnoise.Leveragingbit-slicingandaccumulator-awareoptimizations,weshowthatADCresolutioncanbereducedfrom19to7bitsonResNet18withoutaccuracydegradation.Wefurtherprovideasystem-levelanalysislinkingneuralnetworkcharacteristicsbacktocompute-cellparametersandADCdesignconstraints,establishingtheoperationallimitsofcapacitivecharge-domaininference.Finally,wepresentanenergymodeldemonstratinghowreducedADCprecisionandimprovedcharge-domainefficiencyyieldsubstantialsystem-levelenergysavings.Together,theseresultsofferablueprintforscalable,low-poweranalogDNNaccelerators,pushingtheboundariesoffullyon-chipinference. I.I NTRODUCTION ThecomputationalworkloadofmodernDNNsisdominatedbymatrix-vectormultiplications(MVM),whichariseincon-volutional,fullyconnected,andattentionlayers[ 1 ].State-of-the-artmodelsinvolvebillionsofmultiply-accumulate(MAC)operationsacrossmillionsorevenbillionsofparameters[ 2 ],creatingastrongneedforhardwarethatcandeliverbothhighthroughputandenergyefficiency.Toaddressthis,memory-centricarchitecturessuchasprocessing-using-memory(PUM)andprocessing-near-memory(PNM)reducedatamovementbyembeddingcomputationwithinorclosetomemoryarrays,bothofwhichfallunderthebroadercategoryofprocessing-in-memory(PIM)[ 3 , 4 ].AmongPUMapproaches,charge-domaintechniquesstandoutfortheirsuperiorenergyeffi-ciency.Forinstance,SRAM-basedmacrosusing6T/8Tbit-cellsin7nmnodeshavedemonstratedefficienciesashighas5616TOPS/W/b[ 5 ],orusing10T3Cbitcellsat28nmachieving8161TOPS/W/b[ 6 ]forcommonvisionworkloadslikeResNet-18[ 7 ]onImageNet[ 8 ].Atthedevicelevel,emergingmemcapacitivearrayslikeCapRAM[ 9 ]promiseefficienciesexceeding29600TOPS/W/b,leveragingprinciplessuchaschargescreeningandadiabaticrecovery.Incontrast,resistivePUMmacrossuchasReRAMandPCMbasedonestypicallylagbehind,reachingonly336–1344TOPS/W/bduetodevicevariabilityandthehigh-precisionADCoverheadsrequiredforreliablereadout[ 10 , 11 ].Despitetheirefficiency, charge-domainPUMarchitecturesfaceacriticalbottleneck:limitedon-chipmemorydensity.Existingmacrostypicallyprovideonlykilobytestoafewmegabytesofweightstorage,ordersofmagnitudebelowthecapacityrequiredformodernDNNswithbillionsofparameters.Fetchingweightsfromoff-chipDRAMunderminesthecoreenergyadvantageofPUM,incurringsubstantialaccessenergyandlatencypenalties.TheproblemisespeciallysevereinSRAM-baseddesigns:storing1GBin6TSRAMisestimatedtorequire ∼ 400mm 2 ofdieareaandcosthundredsofdollars[ 12 ].Theselimitationshavemotivatedashifttowarddensermemorytechnologiescompatiblewith3Dintegration.Forexample,CapRAMsup-portsmonolithicverticalstackingoverlogic,akintoBitCostScalable(BiCS)NAND-Flash[ 13 ],offeringhigh-density,low-energyanalogMACswithinacompactfootprintsuitableforedgedeployment.Yet,highefficiencyfortheanalogdotproductalonedoesnotsuffice,thedominantenergybottleneckinPUMisoftennottheMACitself,butrathertheADCs[ 14 , 15 , 16 ].Theseconvertersmustdigitizehigh-resolutionanalogcolumnsums,andtheirenergycostscalesexponentiallywithresolution.Inthiswork,wederivedesignrulesforscalable,precision-awarecapacitivePUMsystemssuitableforDNNinference.Ourkeycontributionsare: 1) Wederivetheoreticallimitsonanalogcolumnsumsandshowhowbit-slicingreducesADCprecisiondemands,albeitatthecostofadditionalcomputecycles. 2) WeextendtheA2Q+[ 17 ]algorithmtosupportslice-wiseregimes,enablingtightADCprecisionbudgetswithoutdegradinginferenceaccuracy. 3) Wedevelopananalyticalframeworktoquantifytheeffectsofgeometricalvariation,programmingimpreci-sion,andreadoutnoiseonsignalfidelityincapacitivecharge-domainsystems. 4) WedemonstratethatcapacitivePUMarchitecturescanapproachthefundamentalnoiselimitmoreeffectivelythanresistivecounterparts,unlockingnewopportunitiesforultra-efficienton-chipinference.Together,thesecontributionsformablueprintfornext-generationPUMacceleratorsthatcaneventuallysupportbillion-parameterDNNson-chipwithintightedgeenergybudgets. Fig.1 providesahigh-levelviewofthecapacitiveacceleratoranditsdigitalperipheryforaccommodatingslice-wisequantization( Sec.III-C ). II.P RELIMINARIES Thischapterreviewsthekeyconceptsunderlyingouranal-ysis.WefirstoutlinethecomputationaldemandsofDNNin-ference,focusingonthecentralroleofmatrix-vectormultipli-cations.Next,wediscussquantizationtechniquesthatreduceinferencecostbyencodingweightsandactivationsinlow-precisionformats.Finally,weintroducecharge-basedPUMarchitecturesthatperformMVMsefficientlyusingcapacitivememories. A.ModernDNNInference Atitscore,inferenceinmodernDNNsreducestorepeatedmatrix–vectormultiplications.Convolutional,fullyconnected,andattentionlayerscanallbeexpressedinthisform[ 1 ],whereaweightmatrixmultipliesanactivationvectortoproducethenext-layeroutput,typicallyfollowedbyanonlinearity.ThecomputationalcostofinferenceisthereforeproportionaltothenumberofMACoperations,whichscaleswithboththedepthofthenetworkandthedimensionalityofitslayers.State-of-the-artmodelscontainmillionstobillionsofparameters[ 2 ],leadingtoinferenceworkloadsdominatedbyMVMs.There-fore,efficienthardwareexecutioniscritical.Algorithmictech-niquessuchasquantizationreducethearithmeticprecisionofweightsandactivationswhilepreservingaccuracy[ 18 , 19 , 20 ].Awidelyadoptedconfigurationuses4-bitweightsand8-bitactivationswithhighbitaccumulations,achievinghighaccuracyacrossdiversetasks[ 19 , 20 , 21 ].Weightquantizationisgenerallymorerobustthanactivationquantization[ 22 , 23 ],sinceweightsarestaticandcanbequantizedofflinewithminimalaccuracyloss[ 24 , 25 , 26 ].Incontrast,activationsvarydynamicallyatruntime,makingaggressivelow-bitquan-tizationsubstantiallymorechallenging[ 18 , 27 , 28 ].SuchquantizationstrategiesformthealgorithmicfoundationforcapacitivePUMsystems. B.QuantizingWeightsandActivations Inferenceefficiencyhingesonquantizationofweightsandactivations.Configurationslike W4A8 (Section II-A )high-lighttheprecision–efficiencytradeoff.Next,weexaminethestrategiesthatrealizetheserepresentations.Differentstrategiesintroducequantizersatdistinctstagesofthetraining–deploymentpipeline.Post-trainingquantiza-tion(PTQ)[ 29 , 30 , 31 ]appliesdiscretizationtoafrozenmodelwithoutfurtheroptimization,buttypicallyrequireshigherprecisionorextensivecalibrationtopreserveaccu-racy[ 32 , 33 ].Attheotherextreme,fullyquantizedtraining(FQT)[ 34 , 35 , 36 ]enforceslowprecisionacrossalltensors,includinggradients,ensuringclosealignmentwithhardwarearithmetic,thoughatthecostofnoisyweightupdates.Acompromiseisquantization-awaretraining(QAT)[ 37 , 38 , 39 ],inwhichtheforwardpassisquantizedduringfine-tuningwhilethebackwardpassremainsinfullprecision.Forsub-8-bitarithmetic,QATconsistentlyoutperformsPTQandavoidstheoptimizerinstabilitiescommoninFQT[ 36 , 40 ].Forthesereasons,weadoptQATasthequantizationstrategyinthiswork. ADC ADC ADC [ w ] (0) ... [ w ] (L w -1) input buffers PUM crossbar [ x ] (L x -1) [ x ] (0) ... K B y DAC S x DAC DAC DAC DAC DAC DAC ... ≪ S x ×j x Σ ×L w ×Lx ≪ S w ×j w ≪ S w ×j w ... [ y ] recomb. + output buffers ×Lx z (j w ) × Σ S x +log 2 K ... K Σ ADC ... S x ×K + Fig.1.Peripheryfromquantizedinput [ x ] toquantizedoutput [ y ] .Shownisthecrossbarwithdifferentialweights,andthedigitaloperationsneededforslicingrecombination.Notehowasinglenetworkweightrequiresmultiplebitlinesduetodifferentialweights(+&-)andweightslicing( L w ) Quantizationduringtrainingiscommonlysimulatedbyauniformaffinemappingfromhigh-precisiontolow-precisionvalues.AsshowninEquation( 1 ),theoperatorisdefinedbyapositivescalefactor ∆ ∈ R + andanintegerzero-point z ∈ Z .Inputsareroundedtothenearestintegerusinghalf-wayrounding ⌊·⌉ ,thenclippedvia clip( · ,n,p ) totherepresentablerangedeterminedbythetargetbitwidth B ∈ N .Forsignedformatsweset n = − 2 B − 1 , p =2 B − 1 − 1 ;forunsignedformats n =0 , p =2 B − 1 .Foravector u ∈ R K wedefine Q B ( u ):=clip �� u ∆ � + z,n,p � . (1)Forbrevity,thequantizedvectoriswrittenas [ u ]:= Q B ( u ) ∈ Z K ,anditsde-quantizedcounterpartiswrittenas ˆ u :=∆ � [ u ] − z � ,sothat u ≈ ˆ u .Eachquantizedentryisboundedinmagnitude.Foranyindex i ∈{ 1 ,...,K } ,theoutputof( 1 )satisfies | [ u ] i |≤ 2 B − δ u − ¯ δ u . Here,theindicator δ ( · ) =1 forsignedrepresentationsand 0 otherwise,whileitscomplement ¯ δ ( · ) =1 − δ ( · ) appliesintheunsignedcase.DuringQAT,theforwardpasssubstituteseachfloating-pointtensorwithitsde-quantizedversion.Gradientsareevaluatedwiththestraight-throughestimator(STE)[ 41 ],enablingsimultaneouslearningofnetworkweightsandquan-tizationparameters[ 39 , 42 , 43 ]. C.ChargeDomainPUMusingCapacitiveDevices ThegeneralconceptofchargedomainPUM[ 6 , 44 , 45 , 46 ]buildsuponthecharge-voltagerelationshipofacapacitor Q = C × V in ,wheretheinputsoftheMVMareencodedasthevoltage V in andtheweightsarestoredasacapacitance C .Thecharge Q isaccumulatedonabitlineovermanycapacitivecellsanddeliversthefinalresultoftheMVMaccordingto � Q i .Thischargeisconvertedintoavoltageandthenconvertedbacktothedigitaldomain,byusingananalog-to-digitalconverter.Theimplementationofthevariablecapacitancecandifferdependingontheconcept.InSRAMbasedaccelerators,thecapacitorisrealizedbyMIMorMOMcapacitorsintheback-end-of-line(BEOL),witha6Tor8TSRAMcellstoringa1bitvalueoftheweight[ 6 ].Thereareseveralimplementationsofmemcapacitivesystems,whereavariablecapacitancecanbeimplementedwithanintegratedstoragecapability,e.g.,ferro-electricbased[ 47 ],MOScapacitorbased[ 48 , 49 ],orchargescreeningbasedmemcapacitors[ 9 ].Chargescreeningbasedmemcapacitors(CapRAM)havetheadvantageofobtainingalargeon/offratiocomparedtootherimplementations(insinglecrystallinesiliconupto60).Theyarebasedonthreelayers:aninputgate,ashieldinglayer,andaread-outelectrode,whichisconnectedtothebitline.Tocontrolthecapacitivecouplingfromtheinputelectrodetotheread-outelectrode,amemorylayerisplacedbetweentheinputgateandtheshieldinglayer,whichmaybebasedoneitheraferroelectricoracharge-trappingmechanism.Suchamemcapacitiveimplementationnotonlyenablesintegratedstoragecapability,butalsoofferstheadvantageofhighermemorydensitycomparedtoSRAM-baseddesignsbysup-portingcost-effective3Dmonolithicscaling,similarto3DNANDflash[ 13 ].Forthefollowinganalysis,weassumeageneralmemcapacitivedevicewithamaximumcapacitanceof C max =1fF andanareaof 1 µ m 2 ,whichiscapableofstoring 2 B w states,correspondingtoa B w bit weightvalue.EachmemcapacitivedevicehasacertainON/OFFratio(ra-tiobetweenthemaximumcapacitance C max andtheminimumcapacitance C min ).Ananalysisofhowthisaffectstheoverallreadoutperformanceisdeliveredlater. D.ColumnSumResolutionvsADCEnergy ThepowerefficiencyofanADC[ 50 , 51 , 52 ]istypicallyquantifiedbytheWaldenfigureofmerit(FOM)ortheSchreierFOM,wheretheformerisanempiricalmeasureforcircuitsthatarenotfullylimitedbythermalnoise(i.e.,ADCswithlowtomoderatebitwidths).TheWaldenFOMisdefinedasfollows,where B y istheADC’sbitwidth: FOM W = E conv 2 B y [ FOM W ]=J conv . - step (2)Therefore,theconversionenergyscaleswith 2 B y .Duringthepast20years,theWaldenFOMforADCshasimprovedbyafactorof7500[ 53 ],partlyduetotechnologyscalingandpartlyduetodesignimprovements.Intheearly2000s,whenthetechnologynodewasaround350nm,atypicalvaluefor 6 7 8 9 10 11 12 13 14 15 16 ADC Resolution B y (bit) 0 20 40 60 80 100 Top-1 Accuracy (%) 0 100 200 300 400 500 Overflows per Dot Product Fig.2.Top-1classificationaccuracyandaveragenumberofaccumulatoroverflowsperdotproductasafunctionofADCresolution B y .Resultsareshownforasingle-layerquantizedneuralnetworktrainedonMNIST[ 54 ]with8-bitweightsandbinaryinputs.AtlowADCresolutions,frequentoverflowseverelydegradesaccuracy,whileincreasing B y beyond12bitseliminatesoverflowsandrestoresfullaccuracy. theWaldenFOMwasintherangeof 1pJ / conv . –step ;in2019numbersof 0 . 4fJ / conv . –step wereobtained[ 53 ].AccordingtothethermallimitoftheSchreierFOM,anincreaseofthetotalenergyperconversionproportionalto 4 B y isrequired[ 51 ],anditbecomesthedominantenergycontributionforhigherbitwidth( > 10bit ).AdetailedanalysisonthethermalenergylimitforacapacitivePUMsystemfollowsin Sec.IV-B .III.R EDUCING ADCR ESOLUTION R EQUIREMENTS ToensurereliableinferenceonPUMaccelerators,theADCresolutionmustbalancetwocompetingrequirements:itmustbewideenoughtoavoidoverflow,yetnarrowenoughtominimizeenergyconsumption.Inthischapter,wederivetightanalyticalboundsonthecrossbarcolumnsumthatcharacterizethistrade-offandtherebydeterminetheminimumADCresolutionunderthefull-precisionguarantee(FPG).TheFPGrequiresthateveryvaliddot-productduringinferencemapstoauniquedigitalcode,ensuringfunctionalcorrectnesswithoutoverflowerrors[ 16 , 55 ].Whileoverflowisnegligiblewithhigh-precisionaccumulators( ≥ 16 bits),reducingtheaccumulatorbitwidthcausesoverflowprobabilitytogrowexponentially,leadingtosevereaccuracydegradation[ 17 , 56 ].Thiseffectisillustratedin Fig.2 ,whichshowsresultsforaquantizedsingle-layerDNNonMNIST[ 54 ].SeveralworkshaveattemptedtocircumventtheFPGre-quirement,butoftenunderunrealisticassumptions.AnaturalstrategyistorescaletheADCrangetomatchtheinputquan-tizerofthesubsequentlayer[ 55 ].Conceptually,thisalignstheADCoutputwiththenetworkactivations.However,practicaldeploymentwouldrequirescalingnotonlypercrossbarbutalsoperoutputcolumntoaccommodatechannel-wiseweightquantization[ 19 , 21 , 39 ].Consequently,eachbitlinecoulddemandvastlydifferentADCranges,fromaslittleas 0 . 02% ofthedynamicrangeuptonearlythefullscale,renderingfine-grainedper-columnscalinginfeasibleinhardware. AmorepracticalalternativeistoalignthetheoreticalmaximumaccumulatorvaluewiththechosenADCresolution,therebyavoidingimpracticalhardwarespecialization.Tothisend,wefirstderiveconservativeupperboundsoncolumnsumsdirectlyfromoperandbitwidths.Wethentightentheseboundsviabit-slicing,partitioningthecomputationintolower-resolutionsegmentsthatbetterexploitADCprecision.Finally,wereformulatetheboundsintermsofslice-wiseweightcontributions,whichallowsoptimizationmethodssuchasQATtoguaranteethat,forafixedADCresolution,overflowisprovablyavoidedduringinference.Forconcreteness,wequantifytheseboundsunderthequan-tizationsettingintroducedin Sec.II-A ,namely W4A8 :4-bitsignedweightsand8-bitunsignedactivations.Weassumeacolumnlengthof K =128 ,consistentwithwidelyadoptedPUMconfigurations[ 14 , 57 , 58 ]. A.InitialBoundfromOperandDataTypes Aconservativeupperboundonthecolumn-wiseaccumu-lationinanalogcrossbarscanbedirectlyinferredfromtherepresentationallimitsofthequantizedoperands.Let K ∈ N denotethecrossbarcolumnlength.Let [ w ] , [ x ] ∈ Z K bethequantizedweightsandactivations,rep-resentedwithbitwidths B w and B x ,respectively,asdescribedin Sec.II-B .OnecolumnofthePUMcrossbarcomputesadotproduct [ y ]= � [ x ] , [ w ] � = K � i =1 [ x ] i [ w ] i . (3)whichmustliewithintherepresentablerangeofthecolumnADC.TosatisfytheFPG,theresultmustobeytheconstraint: − 2 B y − 1 ≤ [ y ] ≤ 2 B y − 1 − 1 , (4)where B y istheeffectiveresolution(inbit)oftheADCoutput.Sinceinputvaluescanvaryarbitrarilyatinferencetime,weboundtheworst-caseaccumulationmagnitudeusingthetriangleinequality: | y | = | K � i =1 [ x ] i [ w ] i |≤ K � i =1 | [ x ] i || [ w ] i | (5) ≤ K · (2 B x − δ x − ¯ δ x ) · (2 B w − δ w − ¯ δ w ) (6) ≤ 2 B y − 1 − 1 . (7)Tostreamlinesubsequentderivations,wedefinethemaximumvalueperproductas G p =(2 B x − δ x − ¯ δ x ) · (2 B w − δ w − ¯ δ w ) .Solvingfortheminimumrequiredresolution B y ,weobtain: B y ≥ � 1+log 2 � K · G p +1 �� (8)Here, ⌈·⌉ denotesceilingrounding.Inthe W4A8 case( K =128 , B w =4 , B x =8 ),thisyields B y =19 ,whichfarexceedstypicalPUMADCresolutions( ≤ 10 bit)duetoenergy-areascaling[ 14 , 15 , 16 ],aselaboratedin Sec.II-D . col 1 x=x (1) ×2 1 +x (0) Unsliced w=w (1) ×2 1 +w (0) InputonlyWeightonlyBoth Operations col 2cycle 1cycle 2 ×××××××××xw col 1col 2 Slicing Scheme x (1) wwx (0) xxw (1) w (0) x (1) x (1) x (1) x (1) w (1) w (0) w (1) w (0) BitsperMAC y=x×w Con-versionsper Row 42211224 Fig.3.Bit-slicingtrade-offsfora2bit × 2bitdotproduct.Operandsaresplitintohigh( x (1) ,w (1) )andlow( x (0) ,w (0) )bits.Eachcolumnshowstheproductsevaluatedinonecrossbarcolumnandonecycle.FewerbitsperslicerelaxtheADCresolutionbutincreasecyclesandconversions. B.ImprovingBoundviaBit-Slicing As19bitresolutionisimpracticalinoursetting,weaimtoreducethecolumn-sumresolutionwithoutsacrificingexact-ness.Toachievethis,wedecomposebothinputsandweightsintolower-bitwidthcomponents[ 58 , 59 , 60 ].Specifically,lettheoriginalbitwidthsofactivationsandweightsbe B x and B w .Choosedivisors S x | B x and S w | B w where S x and S w aretheslicewidthsofactivationsandweightsrespectivelyandsettheslicecounts L x = B x /S x and L w = B w /S w .For [ u ] ∈ Z definetheslicingoperator: S B,S ([ u ]):= � [ u ] (0) ,..., [ u ] ( L − 1) � (9)sothat [ u ]= L − 1 � j =0 2 jS [ u ] ( j ) , (10)wherethemost-significantsliceisinterpretedassignedwhen-ever [ u ] issigned.Inputactivationsandweightsareslicedwith S B x ,S x ([ x ]) and S B w ,S w ([ w ]) ,respectively.Substitutingthesliceexpansionsintothedotproductof Sec.III-A yields: [ y ]= L x − 1 � j x =0 L w − 1 � j w =0 2 j x S x + j w S w � [ x ] ( j x ) , [ w ] ( j w ) � . (11)Eachinnerproductontherightinvolvesonly S x bitand S w bitoperands.Applyingthefull-precisionguaranteetothetermindexedby ( j x ,j w ) thereforerequiresaminimumcolumnsumresolutionof: B ( j x ,j w ) y ≥ � 1+log 2 � K · G ( j x ,j w ) p +1 �� (12)withtheperproductmaximum G ( j x ,j w ) p =(2 S x − δ ( jx ) x − ¯ δ ( j x ) x ) · (2 S w − δ ( jw ) w − ¯ δ ( j w ) w ) .Thusthecolumnsumresolutiondependsontheslicewidthsratherthanonthefulloperandwidths.Returningtoourillustrative W4A8 dot-productexample( K =128 ; B w = S w =4 ,signed; B x =8 ,unsigned)withtheconventionalchoiceof S x =1 [ 14 , 58 , 61 ],therequired outputprecision B y isreducedfrom19bitsto12bits.With S x =1 ,thisschemeeffectivelydecouplestheinputprecisionfromtheresolutionconstraintsimposedbytheADC.Nevertheless,bit-slicingintroducestrade-offs. Fig.3 visu-alizesthesetrade-offsforasimplified2bitactivationand2bitweightexample.FinerslicingreducestheADCresolutionrequirement.However,itproportionallyincreasesthenumberofconversionsbyafactorof L x L w .Theslicescanbeprocessedtemporally,spatially,orthroughahybridscheme.ContemporaryPUMdesignstypicallyadoptcombinationsoftheseprocessingstrategies.Recentadvancementsalsoexploitbit-levelsparsitybyskippingzero-valuedslices,significantlyacceleratingcomputationscomparedtonaivebit-slicedimple-mentations[ 62 , 63 , 64 ]. C.Slice-WiseResolutionTightening Whileacolumn-sumresolutionof B y =12 bitrepresentsasubstantialreductionfromtheoriginal 19 -bitbaseline,itremainscostly( Sec.II-D ).Topushbeyondcoarsebit-slicing,weextendA2Q+[ 17 ]byenforcingslice-specificaccumulatorconstraints.Restatingthecolumn-sumboundfrom Eq.(8) ,thequantizedweightvector [ w ] mustsatisfy K � i =1 | [ x ] i || [ w ] i |≤ (2 B x − δ x − ¯ δ x ) ·∥ [ w ] ∥ 1 ≤ 2 B y − 1 − 1 . (13)whichimposestheglobalbudgetonthe ℓ 1 –normofthequantizedweightvector, ∥ [ w ] ∥ 1 ≤ 2 B y − 1 − 1 2 B x − δ x − ¯ δ x . (14)A2Q+strengthensthisconstraintbyintroducingazero-centeringconditionontheweights, � i [ w ] i =0 .Thispropertyallowstheaccumulator’sfulldynamicrangetobeutilizedandremovesdependenceontheinputsign,yieldingalessrestrictivebound: ∥ [ w ] ∥ 1 ≤ 2 B y − 2 2 B x − 1 , (15)asformalizedinProposition3.1of[ 17 ].Comparedtoouroriginalbound,thisbudgetcanbeupto 4 × largerinlow-bitactivationregimes,significantlyalleviatingpressureonmodelweights.Toenforcetheboundduringtrainingwithoutdegradingaccuracy,A2Q+appliesasymmetricquantization-awarereparameterization: ˆ w =∆ ·Q B w ( w ) , (16) w = v − µ v ∥ v − µ v ∥ 1 · min( g,G y ) , (17) µ v =1 K K � i =1 v i ,G y =∆ · 2 B y − 2 2 B x − 1 . (18)Here,thesubtractionof µ v enforceszero-centeringdirectlyinthereparameterization,ensuringthatthequantizedweights satisfytheimprovedbound.Insteadofusingtheroundtonear-est,A2Q+roundsthescaledfloatingpointweightstowardszero,whichensures ∥ [ˆ w ] ∥ 1 ≤∥ w ∥ 1 ,whichwedenoteby ⌊·⌋ .Theformulationin Eq.(17) drawsinspirationfromtheweightnormalizationreparameterizationintroducedin[ 65 ],whereaweightvectorisexpressedas w = g · v / ∥ v ∥ ,therebyenablingthedecoupledoptimizationofmagnitude g anddirection v / ∥ v ∥ .Weextendthisquantization-awareschemetooperateonindividualbitslices.Usingtheslicingoperatorfrom Sec.III-B ,theslicedrepresentationofthequantizedweights [ w ] isgivenby S B w ,S w ([ w ])= � [ w ] (0) ,..., [ w ] ( L w − 1) � . (19)Duringtraining,eachlatentslice w ( j ) with j ∈{ 0 ,...,L w − 1 } isparameterizedbyadistinctlatentdirectionvector v ( j ) ∈ R K andmagnitude g ( j ) ,whilesharingacommonstepsize ∆ ∈ R .EachsliceisindependentlyprojectedontotheA2Q+feasiblesetdefinedbytheslice-wise ℓ 1 –normbudget G y =∆ · 2 B y − 2 2 S x − 1 (20)andquantizedaccordingto Eq.(16) .Incontrasttotheoriginalquantizer,wereintroducemeansubtractionbymodifyingtheA2Q+updateruleto ˆ w ( j ) =∆ ·Q S w � w ( j ) � + µ v ( j ) (21)IntheoriginalA2Q+formulation,meansubtractionimplicitlyconstrainstheweightvectortolieona ( K − 1) -dimensionalhyperplane,therebyreducingthemodel’sdegreesoffree-dom[ 66 ].Thisreductionmayimpairexpressivity,particularlyforsmall K .Byreintroducingthemean,wepreservethefulldimensionalityoftheweightvector,atthecostofonlyoneadditionaldigitaldotproductperanalogmatrix–vectormultiplication.Initializationbeginswithper-channelcalibrationusingtheOptimallyClippedTensorsAndVectors(OCTAV)al-gorithm[ 42 ],whichdeterminesthefull-precisionscalingfactor ∆ .Thequantizedweightsarethenpartitionedvia S B w ,S w ( · ) ,andtheEP-initprocedure[ 17 ]isappliedtoini-tialize ( v ( j ) ,g ( j ) ) inaccordancewith Eq.(20) .Inlinewiththatframework,boththescalingfactor ∆ andtheslice-wisemagnitude g ( j ) areparameterizedexponentially.AcompletederivationandtheoreticalmotivationforEP-initisprovidedinColbertetal.[ 17 ].Finally,weadopttheregularizationof[ 17 ]penaltytopre-ventslice-wisemagnitudesfromsaturatingwhen g ( j ) >G y : R = σ ( g − G y ) ,σ ( z )=max { z, 0 } . (22)Theoverallregularizationcontributionisthendefinedas L reg = � l � i � j R l,i,j ,where j indexesthesliceofthe i -thoutputchannelinthe l -thlayer.Duringtraining,thispenaltyisintorducedsuchthat L total = L task + λ L reg ,where L task isthespecifictasklossand λ isaconstantscalar. 4 5 6 7 8 9 10 11 12 ADC Resolution B y (bit) 90 91 92 93 94 95 Top-1 Accuracy (%) Float32 accuracy ceiling S w =1 S w =2 S w =4 0 20 40 60 80 100 Weight Sparsity (%) Fig.4.Top-1accuracyofResNet18onCIFAR-10asafunctionofADCresolutionfortheW4A8configurationundervaryingweightslicewidths.Naiveclippingfailsonceresolutionfallsbelowthetheoreticalbound B y from Eq.(12) ,whereasourslice-wiseA2Q+extensionsustainshighaccuracy.Notably,narrowerslicewidthsenablestrongerrecoveryatfixedsparsitylevels. D.EmpiricalEvaluation WeassesstheeffectivenessofourapproachonaResNet18model[ 7 ]pretrainedonCIFAR-10[ 67 ].Theevaluationcon-sidersADCresolutionsbetween3and12bitsunderthecon-figurationoutlinedin Sec.III-B ,withweightsfixedto4bits( B w =4 ).Theweightslicewidthisvariedas S w ∈{ 1 , 2 , 4 } ,whiletheactivationslicewidthremainsfixedat S x =1 .Intotal,60settingsareexplored,eachrepeatedthreetimeswithdifferentrandomseedstoensurestatisticalrobustness.ToadaptResNet18forCIFAR-10,wereplacethefirstconvolutionwitha 3 × 3 kernel,stride1,andpadding1,andremovetheinitialmax-poolinglayertopreservespatialresolution.Fine-tuningisperformedusingSGDwithmomentumover100epochs,batchsize256,weightdecay 1 e − 5 ,andaninitiallearningrateof 1 e − 3 ,decayedbyafactorof0.1every30epochs.Further,wesetthescalescalaroftheregularizationtermdefinedin Eq.(22) as λ =1 e − 3 ,following[ 17 ].NaivequantizationcausessevereaccuracydegradationoncetheADCresolutiondrops1bitbelowthethreshold B y .Thiscanbealleviatedbyreducingtheslicewidth( S w =1 or 2 )orbyapplyingslice-awaretrainingstrategies.Asshownin Fig.4 ,ourextensionofA2Q+preserveshighaccuracyacrossallres-olutions.Forinstance,with S w =4 and B y =8 ,aneffectiveallocationofonly ∼ 2 bitsperweightissufficienttomatchthefull-precisionbaseline.Overall,theproposedmethodreducestherequiredcolumn-wiseaccumulationresolutionfrom19bitstoaslowas7–9bits,withoutsignificantlossinaccuracy.Theseresultsareconsistentwithpriorfindings[ 68 , 69 , 70 ]showingthat2-bitquantizationcanpreserveaccuracyinlarge-scalearchitecturessuchasTransformers[ 71 ]andImageNet-trainednetworks[ 8 ].Ourframeworkgeneralizestheseinsightsbyindirectlysupportingadaptive,per-weightbitwidthassign-ments,e.g.,mixing2-and4-bitweights,whilerespectingslice-levelandglobal ℓ 1 constraints.Thisaddedflexibility MSB LSB [y] (0) [y] (1) [y] (2) [y] (3) 2 0 × +2 1 × +2 2 × +2 3 × [y] = 2 0 2 1 2 2 2 3 2 4 2 5 2 6 LSB error amplifiedby 2 3 (<< 3 bit shift) Fig.5.Exampleofanerroneousbit-serialMACoperation.Asingle-biterrorintheMSBslicecanseverelydistorttheresultbyamplifyingtheimpactoftheerrorandsuppressingthecontributionoflower-significanceslices.Inextremecases,thefullcontributionoftheLSBslicesmaybeerasedduetotheleft-shiftamplification. yieldsastrictlymoreexpressivequantizationschemethanuniform-bitmethods,suggestingimprovedperformanceinmorecomplexsettings.Futureworkshouldvalidatethesefind-ingsonabroadersetofarchitectures,hardwareconfigurations,andtaskstofurtherassessgenerality.IV.L INKING H ARDWARE P ARAMETERSWITH DNNN OISE T OLERANCE Inthischapter,weestablishquantitativelimitsonthetoler-anceofDNNstohardware-inducednoise,focusingonweight-storageimperfections(stemmingfromgeometricalvariationandprogrammingnoise)andonADCread-outnoiseincapacitivePUMdevices.Theselimitsareevaluatedacrosscrossbardimensionsrangingfrom K =128 to K =8192 andformultipleoperandbitwidths.Thederivedconstraints,mostnotablytherequirementthatbothweightvariationandread-outnoiseremainwithinthe (3 σ ≤ 0 . 5LSB) bound,serveasafundamentalcriterionforreliableinferenceandformthebasisfortheupperboundonenergyefficiency,whichwillbeaddressedinthefollowingchapter.Buildingontheframeworkintroducedin Sec.III ,weconsiderbit-slicedarithmeticforanalogMVMs,whereerrorsinthemostsignificantbit(MSB)slicesareparticularlydetrimentalduetopower-of-twoweight-ing.AsingleMSBerrorcanbeamplifiedintolargeactivationdeviations(see Fig.5 ),propagatingthroughthenetworkandsignificantlydegradinginferenceaccuracy.Tomitigatethis,weimposestrictconstraintsonleastsignificantbit(LSB)detectionerrorsduringeverybit-slicecycle.Furthermore,tosafeguardinferenceaccuracyinmodelssuchasResNet-18[ 7 ],weemployatwo-prongedstrategythatcombinesnoise-awaretraining,achievedbyinjectingGaussiannoiseintothedot-productformulationof Eq.(11) asin[ 16 ],therebyenhancingnetworkrobustness,withastrictrequirementthatthecombinedweight-storageandread-outnoiseremainsbelow 0 . 5LSB atthethree-sigmalevel,consistentwith[ 16 , 72 ]. W± σ CD R± σ R A=L×W± σ A l C σ LER d± σ d L± σ CD Fig.6.Platecapacitorwithgeometricalvariationindielectricthickness σ d andareavariationduetocriticaldimensionvariation( σ cd ),lineedgeroughness σ LER withacorrelationlength l C andcornerradiusvariation σ R . Underthequantizationandbit-slicingschemeof Sec.III ,weassumea W4A8 MVMisdecomposedinto L x =8 smaller W4A1 MVMs,and,followingconservativeassumptions,showthattherequiredADCresolution B y increasesbyatmostonebitwheneverthecrossbarsize K doubles. A.GeometricalVariations Eachcapacitancedependsonthesurfacearea( A ),thedielectricconstant( ϵ r )andthethickness( d )oftheinsulatoraccordingtotheformula C = ϵ 0 ϵ r · A d .Thecapacitanceisthereforepronetogeometricalvariationsoftheareaandthickness,asshownin Fig.6 .Herewegiveanestimateofthevariationsthatonecanexpectforanexemplaryareaof 1 µ m 2 andadielectricthicknessof 10nm .InCMOSprocessing,thephysicalgateshapedeviatesfromitsdrawngeometryduetolimitationsinlithographyandetching.Themostsignificantsourcesofthisvariationarecriticaldimension(CD)variability,lineedgeroughness(LER),andcornerrounding.CDvariationreferstofluctuationsintheprintedgatelengthandwidth,typicallycausedbyexposureandetchnonuniformity.LERintroducesshort-range,stochasticwavinessalonggateedgesbecauseofresistbehav-iorandetchchemistry.Cornerroundingarisesfromopticaldiffractionlimitsandcausescurvedtransitionsatoriginallysquarecorners.Toquantifytheeffectofthesemechanismsonthegatearea,webeginwiththenominalgateareaexpression A = L · W andpropagatevariationinbothlengthandwidth.Foranominallysquaregateof L = W =1 µ m ,thestandarddeviationofareaduetoCDvariationis: σ A, CD = � W 2 σ 2 L + L 2 σ 2 W = √ 2 · L · σ CD . (23)A 1 σ CDvariationof σ CD =5nm istypicalfor180nmDUVprocesses[ 73 ],whichyields σ A, CD ≈ 7071nm 2 . ForLER,weestimateareavariationbasedonedgewavi-nesswithfinitespatialcorrelation.ThecontributiontoareavariationfromLERonallfoursidesisapproximatedas: σ A, LER = � 4 L · l C · σ LER . (24)Here, σ LER isthe 1 σ edgeroughnessamplitudeand l c thecorrelationlength.Atthe 180nm node,typicalvaluesare σ LER =2nm and l c =42nm [ 74 ],resultingin σ A, LER ≈ 820nm 2 .Cornerroundingreducesgateareabyreplacingsquarecornerswithquarter-circles.Thenominalarealostperdeviceis: ∆ A =4 R 2 � 1 − π 4 � . (25)Foraroundingradiusof R =60nm ,ascommonlyobservedindeepultraviolet(DUV)lithography[ 75 ],thisyieldsanominallossofabout 3090nm 2 .Iftheroundingradiusitselfvarieslocallywith σ R ≈ 2nm ,thecorrespondingstandarddeviationinareais: σ A, corner =4 · 2 R � 1 − π 4 � · σ R ≈ 206nm 2 . (26)Assumingthesesourcesareuncorrelated,thetotal 1 σ areavariationbecomes: σ A = � σ 2 A, CD + σ 2 A, LER + σ 2 A, corner ≈ 7121nm 2 . (27)Thiscorrespondstoarelative 1 σ variationofapproximately 0 . 71% fora 1 µ m 2 gate,wheretheCDvariationisthedominantsourceofvariation.InmoreadvancedlithographysuchasArFimmersionlithographyatthe 22nm node,theseabsolutevariationbecomelesssignificantduetobetterdepthoffocus.Typicalvaluesforimmersionlithographyare σ CD ≈ 0 . 5nm , σ LER ≈ 2 . 5nm ,and R ≈ 7nm ,with l c around 20 – 30nm [ 76 , 77 , 78 ].Applyingthesameformulas,total 1 σ areavariationforanominal 1 × 1 µ m 2 gatereducestoaround 1118nm 2 (0.11%),assumingthesamecapacitancearea.Filmthicknessvariationatthelocal(intra-die)scaleisacriticalcontributortodevicemismatch.Forhigh-uniformityprocessessuchasatomiclayerdeposition(ALD),local 1 σ thicknessvariationistypically ∼ 0 . 3nm forAl 2 O 3 andHfO 2 ,basedonmetrologystudies[ 79 ].Thecorrelationlengthisintherangeof 8nm to 10nm .Low-pressurechemicalvapordeposition(LPCVD)pro-cessesalsoexhibitstronglocalcontrol,with 1 σ valuesof ∼ 0 . 6nm forthinamorphoussiliconfilms[ 80 ]andcorrelationlengthofaround ∼ 15nm .SimilarresultsareobtainedforLPCVDoxides[ 81 ].Overa 1 × 1 µ m 2 gatearea,theeffectivevariationisreducedbyspatialaveraging.Assumingacorrelationlengthof 10nm andalocal 1 σ variationof 0 . 3nm forALDgrownlayers,thenumberofuncorrelatedsegmentsisapproximately N = � 1000 nm 10 nm � 2 ≈ 10000 ,resultinginanaveragethicknessvariationof: σ d =0 . 3nm √ 10000 ≈ 0 . 003nm . (28) Thisillustrateshowevensub-nanometerlocalvariationcaneffectivelyaverageoutacrosslargerdeviceareas,especiallywhenthecorrelationlengthismuchsmallerthanthefeaturesize.Thetotalvariationingatecapacitancearisesfromlocalfluctuationsinbothgateareaanddielectricthickness.Foraparallelplatecapacitorwith C = ε 0 ε r · A d ,thecombined 1 σ variationcanbeestimatedusingfirst-ordererrorpropagation: � σ C C � 2 = � σ A A � 2 + � σ d d � 2 . (29)Here,weusea 1 σ gateareavariationof σ A =7121nm 2 over A =1 µ m 2 =10 6 nm 2 ,andadielectricthicknessvariationof σ d =0 . 003nm over d =10nm .Thus,theexpectedtotalcapacitancevariation 1 σ isapproximately 0 . 71% ,withtheareavariationcontributingthedominantshare. B.ProgrammingVariation ComparedtoSRAMbasedapproacheswithMIMorMOMcapacitors,whichonlyencountergeometricalvariation,apro-grammablememcapacitorexhibitsalsoprogrammingnoise,whichiscausedbyshotnoiseanddriftdependingonthememorymechanism.Forchargetrapmemories,likeSONOStransistors,avariationof σ ID =20nA foradraincurrentof I D =400nA wereobtained[ 82 ].Thiscorrespondstoathresholdvoltagevariation( σ VT )inthesubthresholdregimeof: σ VT = σ ID I D · kT ηq. (30)With k beingtheBoltzmannconstant, T thetemperature, η =1 . 4 thegateefficiencyand q theelectroncharge.For T =300K weget σ VT =0 . 9mV .InCapRAMthecapacitivechangebetweenamaximum( C max )andminimum( C min )capacitanceisbasedonshiftingofcapacitance-voltage(CV)curvesandusuallychangesinavoltagewindowof V W ≈ 1 . 5V .Therefore,theprogrammingaccuracyofthecapacitanceis: σ C , pgr C max − C min = σ VT V W ≈ 0 . 062% . (31)Thishighprogrammingaccuracycanbeutilizedtocompen-satealsothegeometricalvariations.Basedontherequiredweightbitwidth S W andthematrixsize K therequired σ C, pgr canbeestimated.Toreducethere-quirementsfortheweightbitwidth S w ,theweightissplitintoapositiveandnegativeweight.Thisisalsohelpfulforread-outnoise.Therequired σ C, pgr forachieving 3 σ ≤ 0 . 5LSB erroris(for S w > 1bit ): σ C, pgr C max − C min =1 6 √ K · (2 S w − 1 − 1) . (32) Fig.7 showstherequiredprogrammingvariationversusthematrixsizefordifferentweightbitwidth.Forsmallermatrixsizes( K< 256 ) σ variationsof > 0 . 12% aresufficientfor4bitweights,whileforlargermatrices( K> 1024 )theSONOSprogrammingaccuracyisnotsufficientandlikelymoreweight 0 2048 4096 6144 8192 Column Length K 0.01 0.1 1 C,pgr /(C max C min ) (%) SONOS prog. accuracy dry DUV lith. immersion lith. S w =* 1 2 3 4 5 6 Fig.7.Requiredcapacitancevariancetoachievea 3 σ varianceof0.5LSBfortheweightsfordifferentvectorsizes K andweightslicebitprecisions S w .ThelimitforthegeometricalvariationforDUVlithographyandimmersionlithographyisindicatedbyadashedline,aswellastheSONOSprogrammingvariationduetonoiseanddrift(acapacitanceareaof 1 µ m 2 isassumed).Note,thatthecurvesfor S w =1bit and S w =2bit areoverlappingduetodifferentialprogramming. slicesarenecessary(e.g.2bitweightsforan K =8192 matrix).Anotherkeyaspectforanymemcapacitivedeviceisdriftovertime,whichishighlydependentontemperature.Thegeneralrequirementforanon-volatilememoryistomeetdataretentionfor10yearsat85°C.Inin-memorycomputingsystemsthedriftrequirementsaremuchmoretight,sincetheerrorcanaddupovertheanalogaccumulatorandtheerrorishighlydependentonthechargestateoftheSONOSmemory.ThedriftintermsofcapacitancedependsalsoontheshapeoftheCVcurve,asshownin Fig.11 .AmoreflatCVcurvesleadstolesscapacitivedriftthanasteepone.Also,differentialweightsprogrammedaroundthecenterhelptocompensatedrifttosomeextend.Assumingamaximumerrorof0.5LSBoverthewholeaccumulatorleadstoamaximumalloweddriftof(undertheassumptionofequalcapacitancechangepercell): ∆ C = C max − C min (2 S w − 1 − 1) · K (33)Undertheassumptionofacapacitancechangebetweenmax-imumandminimumof90%within1.5Vthiswouldleadtoamaximumallowedvoltagedriftof: ∆ V =0 . 9 · 1 . 5 V (2 S w − 1 − 1) · K (34)Fora256arrayand4Bitweightsthisleadsto ∆ V =0 . 7 mV .InaSONOSmemorythedriftcanbegreatlyimprovedbyemptyingtheflattrapstates,whichdecayfaster[ 82 ].Evenwiththisimprovementitisexpectedthattheretentionatroomtemperaturecanbeonlymeetforafewhours,untilarefreshisnecessary.AsignificantimprovementtowardsweeksandevenyearscanbeexpectedbyusingbandengineeredSONOS(BE-SONOS),whichreduceschargeleakagebysignificantamount[ 83 ]. Charge integration mode Voltage divider mode Q LSB ,q n K V in C max -C min C par V in C max -C min V in C max -C min V out ,v n V in C max -C min C par V in C max -C min V in C max -C min C dmy Fig.8.Voltagedividerandchargeintegrationmodeforacapacitivearrayincludingparasiticcapacitance.Thedummycapacitors C dmy areincludedforthevoltagedividertocompensatenonlinearity. C.ReadNon-Idealities Capacitivein-memorycomputingarchitecturesaresubjecttovariousnon-idealitiesduringread-outoperationsthatcansignificantlyimpaircomputationalaccuracy.Amongthese,thetwomostcriticalfactorsareread-outnoiseandread-outnonlinearity.Theselimitationsarisefrombothintrinsicphysicalnoisesources,circuit-levelimperfectionssuchasparasiticcomponents,andfundamentaldevicecharacteristics.Afundamentalsourceofnoiseinanycapacitoristhermalnoise,commonlyreferredtoas kTC noise,whichorig-inatesfromthethermalagitationofchargecarriers.Theroot-mean-square(RMS)voltageofthisnoiseisgivenby V rms = � kT/C ,where k istheBoltzmannconstant, T istheabsolutetemperatureand C isthecapacitance.Thisexpressionillustratesthatlowercapacitancevaluesleadtohighernoiseamplitudes,makingsmallcapacitiveelementsparticularlyvul-nerable,butsmallcapacitiveelementsarenecessaryforhighweightstoragedensity.Inpracticalcapacitivememoryarrays,additionalnoisecontributionsarisefromparasiticcapacitances,whichareun-intentionallyformedduetorouting,interconnects,anddevicelayout.Theseparasiticsdonotcarryasignal,butcontributefullytothethermalnoisebudget,degradingthesignal-to-noiseratio(SNR).Becauseofthis,minimizingparasiticeffectsisakeyoptimizationtargetinthedesignofhigh-densitycapacitiveanalogcompute-in-memoryarrays.Also,theminimumpossibleprogrammedcapacitance C min hasnoadditionalinformation,butaddsnoisesimilartotheparasiticcapacitance.Ahigherratioofmaximum C max tominimumcapacitance C min (ON/OFFratio)ofamemcapacitivedevicehelpstoimprovetheoverallread-outnoise.Theschematicin Fig.8 showsarepresentativecapacitivememoryarraywithlabeledparasiticcomponents.Thesepar-asiticsinteractwiththeprogrammedmemcapacitorsduringreadoutandinfluencebothsignalfidelityandenergyefficiency.Capacitivearrayscanbereadusingtwoprincipalmodes: chargeintegrationandvoltagedivision,eachinteractingdif-ferentlywithnoiseandnonlinearity.Inthechargeintegrationmode,thebitline(BL)isheldatvirtualgroundbyatransimpedanceamplifier.Whenaninputvoltageisapplied,allmemorycellcharges,includingthosefromparasiticcapacitanceandtheminimumcapacitanceofeachdevice,areintegratedintheamplifier.Thismeansthattheresultingsignalincludesbothusefulchargeandunwantednoisecontributions.Assumingthateachmemcapacitorcanbeprogrammedbetweenaminimumcapacitance C min andamaximumca-pacitance C max ,with S w bitofweightresolution,thecorre-spondingcapacitiveresolutionis(for S w > 1bit ) C LSB =( C max − C min ) / � 2 S w − 1 � .Onewaytoincreasetheoverallsignal-to-noiseratioistheuseofdifferentialweightsthatareseparatedontwobitlines(see Fig.1 ).Withseparationofthepositiveandnegativerange,thecapacitivestepincreasesbyafactoroftwo: C LSB =( C max − C min ) / � 2 S w − 1 − 1 � .Togetherwithaninputvoltage V in whichisdiscretizedinto S x bit,thechargecorrespondingtooneLSB(leastsignificantbit)ofoutputis(for S w > 1bit ): Q LSB = C max − C min 2 S w − 1 − 1 · V in 2 S x − 1 . (35)Thenoiseonthebitlinedependsonthetotalcapacitanceseenatthenode.Asmentionedinthebeginningof Sec.IV ,thetotalADCbitwidth B y dependsonthegivenmatrixsize K andthebitwidthoftheweightsandinputs.Therefore,thenumberofcapacitivecellsthateffectivelycontributetotheresult( N cap )aregivenas(for S w > 1bit ): N cap =2 B y 2 S w · 2 S x . (36)Thetotalchargenoiseisthereforeundertheworst-caseconditionofamaximumaccumulator: q n = � kT ( K · C min + C par + N cap · C max ) . (37)Inthevoltagedividermode,thememorycelloperatesasonepartofacapacitivevoltagedividerinconjunctionwiththeparasiticbitlinecapacitance.Theoutputvoltageisgivenby: V out = C mem C mem + C par · V in . (38)Thisread-outmodeisinherentlynonlinear,especiallywhentheratiobetween C mem and C par variessignificantly.Tocounteractthisnon-linearity,programmabledummycapacitorswithatotalcapacitanceof C dmy canbeaddedtothebitline,wherethenumberofdummycapacitorsis N cap .Thesedummycapacitorsareprogrammedintheoppositedirectionto C mem andconnectedtogroundduringreadout,effectivelycompen-satingforparasiticvariationsandeliminatingthedependenceon C mem inthedenominator.TheLSBoutputvoltageisthengivenas(for S w > 1bit ): V LSB = C max − C min K · C min + C par + C dmy · 1 2 S w − 1 − 1 · V in 2 S x − 1 . (39) ThecorrespondingRMSnoisevoltageis: v n ≈ � kT K · C min + C par + N cap C max . (40)Theresultingvoltage V out canbeprocessedviaalow-noiseamplifierordigitizeddirectlyusinganADC.Whileamplifica-tionallowsbettercontroloversignallevels,directconversiondemandshighervoltageresolution.Asignificantadvantageofthevoltagedividermethodisthatitdoesnotrequireavirtualgroundamplifier,simplifyingcircuitimplementation.Thereisnodifferenceinsignal-to-noiseratiobetweenthevoltagedividerandthechargeintegratormode.Inordertoim-provethesignal-to-noisevaluestotherequired 3 σ marginforahalf-LSBtransition,averagingoroversamplingisnecessary.Thenumberofnecessaryaverages N av correspondsto: N av = � 6 · q n Q LSB � 2 . (41)Reformulatingthisformuladelivers: N av =36 · kT · ( K · C min + C par + N cap · C max ) (42) · � 2 S w − 1 − 1 � 2 · � 2 S x − 1 � 2 · 1 ( C max − C min ) 2 · V 2in . Fig.9 revealsthenumberofaverages N av fordifferentcapacitiveON/OFFratios( C max /C min )andmatrixsizes(for C par = K · C min , S x =1bit and S w =4bit , C max =1fF and V in =400mV ).AhigherON/OFFratioreducesthenumberofaverages,whilealargermatrixincreasesitlinearly.ItisexpectedforlargearraysthattheON/OFFrationeedstobeatleast > 50 tonotexceed100-200averages,forsmallerarraysintherangeof K< 512 anON/OFFratioof5-10issufficient.Theimprovementintermsof N av withrespecttotheON/OFFratiosaturatesatthelowerendduetothebitwidthrequirementoftheADC( B y )andtheamountofcapacitance C max .Also,theremightbeanoptimalpointofsplittinglargevector-matrixmultiplicationsintosmalleronestoreducethenumberofaveragesforthroughputreasons,whilemakingcompromisesontheparameterdensitybecauseoftheADCoverheadarea.ForferroelectricimplementationsasmemcapacitivearraysitwillbecomecrucialtoimprovetheON/OFFratio,e.g.MFM(Metal-Ferroelectric-Metal)capacitorssufferalowON/OFFratio,duetotheonlyminorchangeofcapacitancewiththeprogrammeddielectricconstant( ≈ 10% )[ 47 ],whichcanleadtohundredsofaveragesevenforsmallarrays.Therefore,anon-linearsemiconductorneedstobeaddedtothesestackstoimprovetheON/OFFratio.AferroelectricmemorycomparedtoaSONOSmemoryhastheadvantageofalargerdielectricconstant(6-7xlarger)andthereforelargermaximumcapaci-tanceperarea. Fig.10 revealsthenumberofaveragesfordifferentcrossbarsizesversusdifferentmultipliedbitwidth S x × S w .Reducingthebitwidthreducesthenumberofaveragesexponentially,whereasthecase S w =1bit isequalto S w =2bit duetoanon-differentialimplementationfor S w =1bit .Therefore,it 0 20 40 60 80 100 ON/OFF Ratio 10 0 10 1 10 2 10 3 Number of Averages N av K=128 K=256 K=512 K=1024 K=2048 K=4096 K=8192 Fig.9.Dependenceofthenumberofaverages N av ontheON/OFFratioofthememcapacitivedevicefordifferentvectorsizes K .An S w =4bit weightsliceand S x =1bit inputsliceisassumed. isalwaysmorebeneficialtodomoreinputbit-slicing,becauseadditionalinputslicesincreasetimelinearly,whileadditionalinputbitsincrease N av exponentially(thesamealsoholdstruefortheoverallenergyefficiency).Forweightslices,thereisacompromisebetweentheparameterdensityandthenumberofaverages N av .Whenitcomestothelatencywithregardstotherequirednumberofaverages, Fig.10 revealsaplotfordifferentmatrixsizesandmultipliedbitwidth S x × S w for20nsperaverageand80nsperaverage.Thelatencycaneasilygoupto 8 µs forlargematrices,butevenwitha 8 µs anda8192x8192matrix,therearestill16.7TOPSperformed,undertheassumptionthatallcolumnsarecalculatedatthesametime.A8192x8192matrixisestimatedtotakeupanareaof0.37mm²ina64layer3DNANDflashtypeofarray,whichcorrespondsto45.1TOPS/mm²,whichiscompeditivetootherresistiveIMCimplementations(fewTOPS/mm²)[ 10 ].TheADCareaneedstobetakenintoaccount,wherelikelymultiplexingbecomesnecessarytoperforma8192columnoperation,whereanestimated10xmultiplexingleadsto4.51TOPS/mm².Withreducednumberofaveragesbyimprovingparasiticcapacitancevaluesinthearrayandreducingthetimespendforeachaveragethisnumberwouldbeimprovedbyalot.Anotherimportantconsiderationforaccurateanalogcompu-tationisthemitigationofreadoutnonlinearity.Aspreviouslydescribed,onecompensationtechniqueforthevoltagedividermodeinvolvestheuseofprogrammabledummycapacitorstolinearizetheread-outpathbycancelingoutparasiticandmemcapacitor-dependentvariations.However,anothersignifi-cantsourceofnonlinearityliesintheinherentcharacteristicsofthememcapacitordeviceitself.CapRAMdevicestypicallyexhibitanonlinearcapacitance-voltage(C-V)characteristic,whichisengineeredtoachieveprogrammablecapacitivestatesthroughvoltage-inducedshifts.Forexample,thecapacitancemaychangebymorethan90%withinavoltagewindow 1 2 3 4 5 6 MAC Bitwidth S w S x (bit) 10 0 10 1 10 2 10 3 Number of Averages N av K=128 K=256 K=512 K=1024 K=2048 K=4096 K=8192 K=* 128 256 512 1024 2048 4096 8192 40 ns 400 ns 4 µs 40 µs Fig.10.Dependenceofthenumberofaverages N av ontheMACbitwidthaccordingto S w and S x anddifferentvectorsizes K .TheON/OFFratioisassumedtobe10here.Note,that S w =1bit isequalto S w =2bit ,because S w =1bit isanon-differentialweight.Therightaxisshowsthecorrespondingconversiontimeforanaveragingcycletimeof40ns ofapproximately 1 . 5V .Givenanominalread-outvoltageof 400mV ,thisresultsinasignificantvoltage-dependentdevia-tionincapacitance,whichtranslatesintooutputerrorsdepend-ingontheprogrammedstate.Anapproachtomitigateeffects,likemismatchandsensitivitytotemperature,istheuseofdifferentialweightcells,inwhichaweightisencodedacrosstwocapacitors—onepositiveandonenegative—operatinginadifferentialmanner.Thistechniquenotonlyreducesmismatchandsensitivitytotemperaturevariations,butalsosignificantlyreducesreadnon-linearity.ThekeyideaistoprogramboththepositiveandnegativecapacitorssymmetricallyaroundthecenteroftheC-Vcurve,wheretheslopeissteepest.IftheC-Vcurveissymmetric,thenvariationsintheslopewithrespecttovoltagecancelouttofirstorder,therebylinearizingtheeffectiveweightread-out.Thisconceptisillustratedin Fig.11 .Onetrade-offofthecenter-symmetricprogrammingstrategyisanincreaseinnoise,sincetheoverallcapacitanceincreases,whiletheamountofsignalstaysthesame(centerprogram-mingcorrespondstoaneffectiveincreasein C min ).V.T RANSLATING R EQUIREMENTSTO E NERGY E FFICIENCY Asmentionedin Sec.II-D ,thebestinclassWaldenFOMrangesnowadaysintherangeof 0 . 4fJ / step [ 53 ].Forthefollowinganalysisitisassumedtobe 1fJ / step .TherequiredbitwidthfortheADCisdeterminedin Sec.III andisde-pendentonthematrixsizeandthebitwidthoftheinputandweight.For S x =1 bitand S w =4 bit,meaninga W4A1 MVM,thebitwidthrequirementfortheADCdependslinearlyonthematrixsize K andis B y =8bit for K =128 and B y =14bit for K =8192 withpotentialofreducingthisnumberwithfurtherresearch.Assuming 1fJ / step thereisaconstantcontributionof 8fJ / OP percapacitivecellfromtheWaldenFOM,independentofthematrixsizeincluding center programming CV negativeweightpositiveweight programming shift Fig.11.Centerprogrammingofnegativeandpositiveweightsallowsforsymmetricslopeerrorstocancelout. theconversionof L x =8 inputslices,whichcorrespondsto 0 . 25fJ · b / OP .Thethermalcontributioniscausedbytheenergysuppliedtothecapacitivedevice,includingthenumberofaverages.Foranypotentialamplificationfollowingthebitline,adynamicamplifier[ 84 , 85 ]wouldbeanenergy-efficientapproachduetoitslowstaticpowerconsumption.Thethermalcontributionfromthecapacitivedeviceisgivenbynumberofaverages,the L x =8 inputslicesandthefactthatthecapacitivedeviceperformstwooperations(summationandmultiplication).Also,onehastoconsiderthateachweightrequirestwocapacitors,onepositiveandonenegative: E cap =8 · N av · Q LSB · V in · 2 B y K +8 · N av · C min · V 2 in . (43)Thefirstterminthesumconsidersalltheenergyforthesupplyingthechargefor 2 B y LSBchargelevelsforthegivenamountofaveragesandbit-slices,whilethesecondtermconsiderstheenergyforchargingallcapacitorswith C min ,duetolimitedON/OFFratioofthecapacitivedevice. Fig.12 revealstheenergy E cap fordifferentmatrixsizesandON/OFFratios.Highenergyefficienciesareobtainedforsmallerarraysanddecreaseforlargerarrays,duetotheincreasedbitwidthrequirementfortheADCandtheSchreierFOM.AhigherON/OFFratiohelpstoimprovetheenergyefficiency. Fig.13 showsthetotalenergyefficiency E tot ,whichincludestheWaldenFOM.ForsmallarraysandthereforelowADCbitwidththeWaldenFOMisdominatingtheenergyperoperationwhileforlargerarraysthethermallimitofthecapacitivedevicebecomesdominating,whichisevenmoredominatingforlowerON/OFFratios.Foranarraysizeof K =256 energyefficienciesof 9 . 5fJ / OP ( 0 . 3fJ · b / OP )areobtained,whilefor K =4096 theefficiencyis 32 . 4fJ / OP ( 1 . 01fJ · b / OP ),assuminganON/OFFratioof50and L x =8 lower-precision W4A1 MVMs. 0 20 40 60 80 100 ON/OFF Ratio 0.01 0.1 1 10 E cap ( fJ · b/OP ) K=128 K=256 K=512 K=1024 K=2048 K=4096 K=8192 K=* 128 256 512 1024 2048 4096 8192 100 10 1 0.1 POPS/W/b Fig.12.Capacitivethermalenergyconsumptionperoperation( E cap )versusON/OFFratioofthecapacitivedevicefordifferentvectorsizes K .Weassume L x =8 inputslicesresultingin 8 × W4A1 MVMs. 0 2048 4096 6144 8192 Column Length K 0.01 0.1 1 10 E tot ( fJ · b/OP ) total memcapacitor ON/OFF=5 ON/OFF=10 ON/OFF=20 ON/OFF=50 ON/OFF=100 Walden FOM 100 10 1 0.1 POPS/W/b Fig.13.TotalenergyperoperationincludingtheWaldenFOMoftheADCversusvectorsize K fordifferentON/OFFratios.Thedashedlinesshowthecapacitivethermalcontribution,whichdominatesforlargermatrixsizesduetotheincreasedADCbitwidthrequirement B y .Weassume L x =8 inputslicesresultingin 8 × W4A1 MVMs. Improvementsonenergyefficiencycanbeobtainedbychoosingsmallercrossbarsizesand/ormoreweightslicesatthecostoflowerparameterdensity.Anotheroptimizationpotentialareimprovementsonthequantisationtoachievelower σ requirementsfortheLSBerrorand/orlowerADCbitwidth B y . Fig.14 showsthedependencyoftheenergyperoperationontheADCbitwidthfora K =8192 matrixforanON/OFFratioof50.Atypical 2 2 B y behavior,accordingtotheSchreierFOM,isvisibleandareductionbyjust2bitfrom14bitreducestheenergyperoperationfrom 1 . 78fJ · b / OP to 0 . 22fJ · b / OP .Infact,thetheoreticallimitofenergyefficiencycanbecalculatedbasedonthesignal-to-noiseratio,giventhattheamountofenergysourcedinacapacitoris: E cap = C · V in2 . (44)Togetherwiththechargenoise,wegetthefollowingnumber 10 11 12 13 14 ADC Resolution B y (bit) 0.1 1 E tot ( fJ · b/OP ) K=8192 10 1 POPS/W/b Fig.14.Totalenergyperoperationforacolumnlengthof K =8192 andreducedbitwidthfortheADC B y .Weassume L x =8 inputslicesresultingin 8 × W4A1 MVMs(inallotherplots B y =14bit wasassumedfor K =8192 ). oflevels( 3 σ ≤ 0 . 5LSB ): 2 B y = C · V in 6 ·√ kTC. (45)Reformulatingthiswiththeenergy,weget: E cap =36 · 2 2 B y · kT. (46)Thisformularepresentsagaintheexponentialdependencyonthebitprecisionforthereadout B y .Forpurelyresistivecross-bararrays,wegetsimilarresultswithagivenmeasurementtime T meas : E res = V in2 R · T meas . (47)Forthenumberoflevels,wegetthefollowing,basedonthermalnoise: 2 B y = V in 6 ·√ 4 kTR ∆ f. (48)Assumingtheeffectivenoisebandwidth ∆ f islimitedbytheamountofmeasurementtimeaccordingto ∆ f =1 / 2 T meas ,weget: E res =36 · 2 2 B y · 2 · kT. (49)Thisproves,atthesamebitwidth B y ,resistivedevicesareatleast2timeslessenergyefficientthancapacitivedevices.Inmanyresitivedevices,likeRRAMortransistorsinweakinversion,thereisalsoshotnoisepresentduetopotentialbarriers,whichleadstoworseenergyefficiencynumbers,accordingtothefollowingrelationshipweget: 2 B y = I · T meas 6 √ qI · T meas . (50)Where I isthecurrentthroughthedevice,whichyieldsaccordingto E shot = I · T meas · V ,withtheappliedread-outvoltage V : E shot =36 · 2 2 B y · q · V. (51)Foraread-outvoltageof V =0 . 4 V ,theresultsare 15 . 4 × thanthecapacitivecase. VI.C ONCLUSIONAND F UTURE W ORK Inthiswork,weinvestigatedthecoretrade-offsincapacitivePUMsystems,focusingoninputandweightprecision,matrixsize,andtheconstraintsimposedbybothquantizationandphysicalnonidealities.Ouranalysisrevealedthatmeetingthecommonlyadoptedfidelityconstraintof 3 σ ≤ 0 . 5LSB placessignificantdemandsonweightprogrammingaccuracy,partic-ularlyasmatrixsizeincreases.Tocompensateforincreasedprogrammingnoiseandgeometricvariationinlargerarrays,additionalweightslicesmayberequiredtopreserveinferencefidelity.Ontheread-outside,theoutputcapacitancefun-damentallylimitstheachievableSNR,makingoversamplingessentialformaintainingaccuracyatlargerscales.WeshowedthatincreasingtheON/OFFratioofthememcapacitivedevicesubstantiallyreducesthenumberofrequiredaveragingcycles,withanON/OFFratioexceeding50becomingnecessaryformatricesofafewthousandrowstoachieveacceptableenergyefficiency.ADCresolutionwasidentifiedasadominantcontributortoread-outenergy.Inthispaper,weoperatedundertheFPGframeworktopreserveexactdigitalequivalence.However,thisconstraintimposeshighbitwidthandenergydemands,especiallyatscale.FutureworkshouldinvestigatequantizationstrategiesthatrelaxtheFPGconstraint,enablingevenlowerADCresolu-tionswithoutsignificantlossinmodelaccuracy.Additionally,developingmethodsthatrelaxthestrict 3 σ ≤ 0 . 5LSB boundcouldquadraticallyreducethenumberofrequiredaverages,therebyimprovingenergyefficiencyandeasingtheburdenonweightwriteaccuracy.Finally,exploringwhethercolumn-sumresolutiontighteningcanbeenforcedusingPTQasamorecost-effectivealternativetoQAT,especiallyforlargemodelswherefullQATisprohibitivelyexpensive[ 21 ],wouldbevaluable.ThesedirectionspromisetounlockfurtherefficiencygainsandbroadenthescalabilityofcapacitivePUMarchitecturesfordeeplearninginference.R EFERENCES [1] V.Sze,Y.-H.Chen,T.-J.Yang,andJ.S.Emer, Efficientprocessingofdeepneuralnetworks .Springer,2020. [2] J.Kaplan,S.McCandlish,T.Henighan,T.B.Brown,B.Chess,R.Child,S.Gray,A.Radford,J.Wu,andD.Amodei,“Scalinglawsforneurallanguagemodels,”2020.[Online].Available: https://arxiv.org/abs/2001.08361 [3] O.Mutlu,S.Ghose,J.G´omez-Luna,andR.Ausavarung-nirun,“Amodernprimeronprocessinginmemory,”in Emergingcomputing:fromdevicestosystems:lookingbeyondMooreandVonNeumann .Springer,2022,pp.171–243. [4] P.Chi,S.Li,C.Xu,T.Zhang,J.Zhao,Y.Liu,Y.Wang,andY.Xie,“Prime:Anovelprocessing-in-memoryar-chitectureforneuralnetworkcomputationinreram-basedmainmemory,” ACMSIGARCHComputerArchitectureNews ,vol.44,no.3,pp.27–39,2016. [5] M.E.Sinangil,B.Erbagci,R.Naous,K.Akarvardar,D.Sun,W.-S.Khwa,H.-J.Liao,Y.Wang,andJ.Chang, “A7-nmcompute-in-memorysrammacrosupportingmulti-bitinput,weightandoutputandachieving351tops/wand372.4gops,” IEEEJournalofSolid-StateCircuits ,vol.56,no.1,pp.188–198,2021. [6] J.Lee,B.Zhang,andN.Verma,“Aswitched-capacitorsramin-memorycomputingmacrowithhigh-precision,high-efficiencydifferentialarchitecture,”in 2024IEEEEuropeanSolid-StateElectronicsResearchConference(ESSERC) ,2024,pp.357–360. [7] K.He,X.Zhang,S.Ren,andJ.Sun,“Deepresiduallearningforimagerecognition,”2015.[Online].Available: https://arxiv.org/abs/1512.03385 [8] O.Russakovsky,J.Deng,H.Su,J.Krause,S.Satheesh,S.Ma,Z.Huang,A.Karpathy,A.Khosla,M.Bernstein,A.C.Berg,andL.Fei-Fei,“Imagenetlargescalevisualrecognitionchallenge,”2015.[Online].Available: https://arxiv.org/abs/1409.0575 [9] K.-U.Demasius,A.Kirschen,andS.Parkin,“Energy-efficientmemcapacitordevicesforneuromorphiccomputing,” NatureElectronics ,vol.4,pp.748–756,2021.[Online].Available: https://www.nature.com/articles/s41928-021-00649-y [10] R.Khaddam-Aljameh,M.Stanisavljevic,J.ForntMas,G.Karunaratne,M.Br¨andli,F.Liu,A.Singh,S.M.M¨uller,U.Egger,A.Petropoulos,T.Antonakopou-los,K.Brew,S.Choi,I.Ok,F.L.Lie,N.Saulnier,V.Chan,I.Ahsan,V.Narayanan,S.R.Nandakumar,M.LeGallo,P.A.Francese,A.Sebastian,andE.Eleft-heriou,“Hermes-core—a1.59-tops/mm2pcmon14-nmcmosin-memorycomputecoreusing300-ps/lsblinearizedcco-basedadcs,” IEEEJournalofSolid-StateCircuits ,vol.57,no.4,pp.1027–1038,2022. [11] W.Li,P.Xu,Y.Zhao,H.Li,Y.Xie,andY.Lin,“Timely:Pushingdatamovementsandinterfacesinpimacceleratorstowardslocalandintimedomain,”in 2020ACM/IEEE47thAnnualInternationalSymposiumonComputerArchitecture(ISCA) .IEEE,2020,pp.832–845. [12] J.Shapiro,“Scalingthememorywall,” https://www.luxcapital.com/news/scaling-the-memory-wall ,July2023,accessed:2025-06-15. [13] A.NitayamaandH.Aochi,“Bitcostscalable(bics)tech-nologyforfutureultrahighdensitystoragememories,”in 2013SymposiumonVLSITechnology ,2013,pp.T60–T61. [14] A.Shafiee,A.Nag,N.Muralimanohar,R.Balasubra-monian,J.P.Strachan,M.Hu,R.S.Williams,andV.Srikumar,“Isaac:Aconvolutionalneuralnetworkacceleratorwithin-situanalogarithmeticincrossbars,” ACMSIGARCHComputerArchitectureNews ,vol.44,no.3,pp.14–26,2016. [15] X.Qiao,X.Cao,H.Yang,L.Song,andH.Li,“Atom-layer:Auniversalreram-basedcnnacceleratorwithatomiclayercomputation,”in Proceedingsofthe55thAnnualDesignAutomationConference ,2018,pp.1–6. [16] W.Zhang,S.Ando,Y.-C.Chen,andK.Yoshioka, “Asim:Improvingtransparencyofsram-basedanalogcompute-in-memoryresearchwithanopen-sourcesim-ulationframework,” arXivpreprintarXiv:2411.11022 ,2024. [17] I.Colbert,A.Pappalardo,J.Petri-Koenig,andY.Umuroglu,“A2q+:Improvingaccumulator-awareweightquantization,” arXivpreprintarXiv:2401.10432 ,2024. [18] R.Krishnamoorthi,“Quantizingdeepconvolutionalnet-worksforefficientinference:Awhitepaper,” arXivpreprintarXiv:1806.08342 ,2018. [19] M.Nagel,M.Fournarakis,R.A.Amjad,Y.Bon-darenko,M.VanBaalen,andT.Blankevoort,“Awhitepaperonneuralnetworkquantization,” arXivpreprintarXiv:2106.08295 ,2021. [20] S.Sharify,U.Saxena,Z.Xu,I.Soloveychik,X.Wang etal. ,“Posttrainingquantizationoflargelanguagemodelswithmicroscalingformats,” arXivpreprintarXiv:2405.07135 ,2024. [21] Y.Li,R.Gong,X.Tan,Y.Yang,P.Hu,Q.Zhang,F.Yu,W.Wang,andS.Gu,“Brecq:Pushingthelimitofpost-trainingquantizationbyblockreconstruction,”2021.[Online].Available: https://arxiv.org/abs/2102.05426 [22] C.Lee,J.Jin,T.Kim,H.Kim,andE.Park,“Owq:Outlier-awareweightquantizationforefficientfine-tuningandinferenceoflargelanguagemodels,”in Pro-ceedingsoftheAAAIConferenceonArtificialIntelli-gence ,vol.38,no.12,2024,pp.13355–13364. [23] J.Lin,J.Tang,H.Tang,S.Yang,W.-M.Chen,W.-C.Wang,G.Xiao,X.Dang,C.Gan,andS.Han,“Awq:Activation-awareweightquantizationforon-devicellmcompressionandacceleration,” ProceedingsofMachineLearningandSystems ,vol.6,pp.87–100,2024. [24] D.Du,Y.Zhang,S.Cao,J.Guo,T.Cao,X.Chu,andN.Xu,“Bitdistiller:Unleashingthepotentialofsub-4-bitllmsviaself-distillation,” arXivpreprintarXiv:2402.10631 ,2024. [25] H.Wang,S.Ma,L.Dong,S.Huang,H.Wang,L.Ma,F.Yang,R.Wang,Y.Wu,andF.Wei,“Bitnet:Scaling1-bittransformersforlargelanguagemodels,” arXivpreprintarXiv:2310.11453 ,2023. [26] A.Abdolrashidi,L.Wang,S.Agrawal,J.Malmaud,O.Rybakov,C.Leichner,andL.Lew,“Pareto-optimalquantizedresnetismostly4-bit,”in ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecognition ,2021,pp.3091–3099. [27] G.Xiao,J.Lin,M.Seznec,H.Wu,J.Demouth,andS.Han,“Smoothquant:Accurateandefficientpost-trainingquantizationforlargelanguagemodels,”in In-ternationalConferenceonMachineLearning .PMLR,2023,pp.38087–38099. [28] C.Guo,J.Tang,W.Hu,J.Leng,C.Zhang,F.Yang,Y.Liu,M.Guo,andY.Zhu,“Olive:Acceleratinglargelanguagemodelsviahardware-friendlyoutlier-victimpairquantization,”in Proceedingsofthe50thAnnualIn-ternationalSymposiumonComputerArchitecture ,2023, pp.1–15. [29] M.Nagel,M.v.Baalen,T.Blankevoort,andM.Welling,“Data-freequantizationthroughweightequalizationandbiascorrection,”in ProceedingsoftheIEEE/CVFinter-nationalconferenceoncomputervision ,2019,pp.1325–1334. [30] M.Nagel,R.A.Amjad,M.vanBaalen,C.Louizos,andT.Blankevoort,“Upordown?adaptiveroundingforpost-trainingquantization,”2020.[Online].Available: https://arxiv.org/abs/2004.10568 [31] J.Zhang,Y.Zhou,andR.Saab,“Post-trainingquantiza-tionforneuralnetworkswithprovableguarantees,” SIAMJournalonMathematicsofDataScience ,vol.5,no.2,pp.373–399,2023. [32] J.Liu,L.Niu,Z.Yuan,D.Yang,X.Wang,andW.Liu,“Pd-quant:Post-trainingquantizationbasedonpredictiondifferencemetric,”2023.[Online].Available: https://arxiv.org/abs/2212.07048 [33] Y.Jeon,C.Lee,andH.-y.Kim,“Genie:Showmethedataforquantization,”in ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecognition ,2023,pp.12064–12073. [34] C.SakrandN.Shanbhag,“Per-tensorfixed-pointquanti-zationoftheback-propagationalgorithm,” arXivpreprintarXiv:1812.11732 ,2018. [35] H.Xi,C.Li,J.Chen,andJ.Zhu,“Trainingtransformerswith4-bitintegers,” AdvancesinNeuralInformationProcessingSystems ,vol.36,pp.49146–49168,2023. [36] X.Sun,N.Wang,C.-Y.Chen,J.Ni,A.Agrawal,X.Cui,S.Venkataramani,K.ElMaghraoui,V.V.Srinivasan,andK.Gopalakrishnan,“Ultra-lowprecision4-bittrainingofdeepneuralnetworks,” AdvancesinNeuralInformationProcessingSystems ,vol.33,pp.1796–1807,2020. [37] M.Courbariaux,Y.Bengio,andJ.-P.David,“Binarycon-nect:Trainingdeepneuralnetworkswithbinaryweightsduringpropagations,” Advancesinneuralinformationprocessingsystems ,vol.28,2015. [38] J.Choi,Z.Wang,S.Venkataramani,P.I.-J.Chuang,V.Srinivasan,andK.Gopalakrishnan,“Pact:Parameter-izedclippingactivationforquantizedneuralnetworks,” arXivpreprintarXiv:1805.06085 ,2018. [39] S.K.Esser,J.L.McKinstry,D.Bablani,R.Appuswamy,andD.S.Modha,“Learnedstepsizequantization,” arXivpreprintarXiv:1902.08153 ,2019. [40] W.Guo,D.Liu,W.Xie,Y.Li,X.Ning,Z.Meng,S.Zeng,J.Lei,Z.Fang,andY.Wang,“Towardsaccurateandefficientsub-8-bitintegertraining,” arXivpreprintarXiv:2411.10948 ,2024. [41] Y.Bengio,N.L´eonard,andA.Courville,“Estimatingorpropagatinggradientsthroughstochasticneuronsforcon-ditionalcomputation,” arXivpreprintarXiv:1308.3432 ,2013. [42] C.Sakr,S.Dai,R.Venkatesan,B.Zimmer,W.Dally,andB.Khailany,“Optimalclippingandmagnitude-awaredif-ferentiationforimprovedquantization-awaretraining,”in InternationalConferenceonMachineLearning .PMLR, 2022,pp.19123–19138. [43] Y.Bhalgat,J.Lee,M.Nagel,T.Blankevoort,andN.Kwak,“Lsq+:Improvinglow-bitquantizationthroughlearnableoffsetsandbetterinitialization,”in ProceedingsoftheIEEE/CVFconferenceoncomputervisionandpatternrecognitionworkshops ,2020,pp.696–697. [44] S.LeeandY.Kim,“Charge-domainstaticrandomaccessmemory-basedin-memorycomputingwithlow-costmultiply-and-accumulateoperationandenergy-efficient7-bithybridanalog-to-digitalconverter,” Electronics ,vol.13,no.3,2024.[Online].Available: https://www.mdpi.com/2079-9292/13/3/666 [45] K.Yoshioka,S.Ando,S.Miyagi,Y.-C.Chen,andW.Zhang,“Areviewofsram-basedcompute-in-memorycircuits,” JapaneseJournalofAppliedPhysics ,vol.63,no.12,p.120802,Dec.2024.[Online].Available: http://dx.doi.org/10.35848/1347-4065/ad93e0 [46] Z.Chen,Z.Wen,W.Wan,A.R.Pakala,Y.Zou,W.-C.Wei,Z.Li,Y.Chen,andK.Yang,“Pico-ram:Apvt-insensitiveanalogcompute-in-memorysrammacrowithin-situmulti-bitchargecomputingand6tthin-cell-compatiblelayout,”2024.[Online].Available: https://arxiv.org/abs/2407.12829 [47] Q.Zheng,Z.Wang,N.Gong,Z.Yu,C.Chen,Y.Cai,Q.Huang,H.Jiang,Q.Xia,andR.Huang,“Artificialneuralnetworkbasedondopedhfo2ferroelectricca-pacitorswithmultilevelcharacteristics,” IEEEElectronDeviceLetters ,vol.40,no.8,pp.1309–1312,2019. [48] D.KwonandI.-Y.Chung,“Capacitiveneuralnetworkusingcharge-storedmemorycellsforpatternrecognitionapplications,” IEEEElectronDeviceLetters ,vol.41,no.3,pp.493–496,2020. [49] T.You,L.P.Selvaraj,H.Zeng,W.Luo,N.Du,D.B¨urger,I.Skorupa,S.Prucnal,A.Lawerenz,T.Mikolajick,O.G.Schmidt,andH.Schmidt,“Anenergy-efficient,bifeo3-coatedcapacitiveswitchwithintegratedmemoryanddemodulationfunctions,” AdvancedElectronicMaterials ,vol.2,no.3,p.1500352,2016.[Online].Available: https://advanced.onlinelibrary.wiley.com/doi/abs/10.1002/aelm.201500352 [50] R.Walden,“Analog-to-digitalconvertersurveyandanal-ysis,” IEEEJournalonSelectedAreasinCommunica-tions ,vol.17,no.4,pp.539–550,1999. [51] B.Murmann,“Theracefortheextradecibel:Abriefreviewofcurrentadcperformancetrajectories,” IEEESolid-StateCircuitsMagazine ,vol.7,no.3,pp.58–66,2015.[Online].Available: https://ieeexplore.ieee.org/document/7168508 [52] B.E.Jonsson,“Usingfigures-of-merittoevaluatemea-sureda/d-converterperformance,”in ProceedingsoftheIEEEInternationalWorkshoponADCModellingandTesting(IWADC)&ADCForum .IEEE,2011,locationandpagenumbersnotspecified. [53] X.Tang,J.Liu,Y.Shen,S.Li,L.Shen,A.Sanyal,K.Ragab,andN.Sun,“Low-powersaradcdesign:Overviewandsurveyofstate-of-the-arttechniques,” IEEETransactionsonCircuitsandSystemsI:RegularPapers ,vol.69,no.6,pp.2249–2262,2022. [54] L.Deng,“Themnistdatabaseofhandwrittendigitim-agesformachinelearningresearch[bestoftheweb],” IEEEsignalprocessingmagazine ,vol.29,no.6,pp.141–142,2012. [55] T.P.Xiao,B.Feinberg,C.H.Bennett,V.Prabhakar,P.Saxena,V.Agrawal,S.Agarwal,andM.J.Marinella,“Ontheaccuracyofanalogneuralnetworkinferenceaccelerators,” IEEECircuitsandSystemsMagazine ,vol.22,no.4,pp.26–48,2023. [56] R.Ni,H.-m.Chu,O.Casta˜nedaFern´andez,P.-y.Chi-ang,C.Studer,andT.Goldstein,“Wrapnet:Neuralnetinferencewithultra-low-precisionarithmetic,”in Inter-nationalConferenceonLearningRepresentationsICLR2021 .OpenReview,2021. [57] S.Negi,U.Saxena,D.Sharma,andK.Roy,“Hcim:Adc-lesshybridanalog-digitalcomputeinmemoryacceleratorfordeeplearningworkloads,”in Proceedingsofthe30thAsiaandSouthPacificDesignAutomationConference ,2025,pp.648–655. [58] A.Ankit,I.E.Hajj,S.R.Chalamalasetti,G.Ndu,M.Foltin,R.S.Williams,P.Faraboschi,W.-m.W.Hwu,J.P.Strachan,K.Roy etal. ,“Puma:Aprogrammableultra-efficientmemristor-basedacceleratorformachinelearninginference,”in Proceedingsofthetwenty-fourthinternationalconferenceonarchitecturalsupportforprogramminglanguagesandoperatingsystems ,2019,pp.715–731. [59] M.LeGallo,S.Nandakumar,L.Ciric,I.Boybat,R.Khaddam-Aljameh,C.Mackin,andA.Sebastian,“Precisionofbitslicingwithin-memorycomputingbasedonanalogphase-changememorycrossbars,” Neu-romorphicComputingandEngineering ,vol.2,no.1,p.014009,2022. [60] S.Diware,A.Gebregiorgis,R.V.Joshi,S.Hamdioui,andR.Bishnoi,“Unbalancedbit-slicingschemeforaccuratememristor-basedneuralnetworkarchitecture,”in 2021IEEE3rdInternationalConferenceonArtificialIntelligenceCircuitsandSystems(AICAS) .IEEE,2021,pp.1–4. [61] A.Nag,R.Balasubramonian,V.Srikumar,R.Walker,A.Shafiee,J.P.Strachan,andN.Muralimanohar,“New-ton:Gravitatingtowardsthephysicallimitsofcrossbaracceleration,” IEEEMicro ,vol.38,no.5,pp.41–49,2018. [62] D.Im,G.Park,Z.Li,J.Ryu,andH.-J.Yoo,“Sibia:Signedbit-slicearchitecturefordensednnaccelerationwithslice-levelsparsityexploitation,”in 2023IEEEIn-ternationalSymposiumonHigh-PerformanceComputerArchitecture(HPCA) ,2023,pp.69–80. [63] M.Shi,V.Jain,A.Joseph,M.Meijer,andM.Verhelst,“Bitwave:Exploitingcolumn-basedbit-levelsparsityfordeeplearningacceleration,”in 2024IEEEInternationalSymposiumonHigh-PerformanceComputerArchitecture(HPCA) .IEEE,2024,pp.732–746. [64] Y.Chen,J.Meng,J.-s.Seo,andM.S.Abdelfattah,“Bbs:Bi-directionalbit-levelsparsityfordeeplearningacceler-ation,”in 202457thIEEE/ACMInternationalSymposiumonMicroarchitecture(MICRO) .IEEE,2024,pp.551–564. [65] T.SalimansandD.P.Kingma,“Weightnormalization:Asimplereparameterizationtoacceleratetrainingofdeepneuralnetworks,” Advancesinneuralinformationprocessingsystems ,vol.29,2016. [66] G.Yang,J.Pennington,V.Rao,J.Sohl-Dickstein,andS.S.Schoenholz,“Ameanfieldtheoryofbatchnormal-ization,” arXivpreprintarXiv:1902.08129 ,2019. [67] A.Krizhevsky,G.Hinton etal. ,“Learningmultiplelayersoffeaturesfromtinyimages,”2009. [68] Y.Li,S.Xu,B.Zhang,X.Cao,P.Gao,andG.Guo,“Q-vit:Accurateandfullyquantizedlow-bitvisiontransformer,” Advancesinneuralinformationprocessingsystems ,vol.35,pp.34451–34463,2022. [69] D.Du,G.Gong,andX.Chu,“Modelquantizationandhardwareaccelerationforvisiontransformers:Acompre-hensivesurvey,” arXivpreprintarXiv:2405.00314 ,2024. [70] M.Sun,H.Ma,G.Kang,Y.Jiang,T.Chen,X.Ma,Z.Wang,andY.Wang,“Vaqf:Fullyautomaticsoftware-hardwareco-designframeworkforlow-bitvisiontrans-former,” arXivpreprintarXiv:2201.06618 ,2022. [71] A.Vaswani,N.Shazeer,N.Parmar,J.Uszkoreit,L.Jones,A.N.Gomez,L.Kaiser,andI.Polosukhin,“Attentionisallyouneed,”2023.[Online].Available: https://arxiv.org/abs/1706.03762 [72] C.-C.Chang,S.-T.Li,T.-L.Pan,C.-M.Tsai,I.-T.Wang,T.-S.Chang,andT.-H.Hou,“Devicequantizationpolicyinvariation-awarein-memorycomputingdesign,” Scien-tificreports ,vol.12,no.1,p.112,2022. [73] G.Vandenberghe,T.Marschner,K.G.Ronse,R.J.Socha,andM.V.Dusa,“CDcontrolcomparisonforsub-0.18-umpatterningusing248-nmlithographyandstrongresolutionenhancementtechniques,”in OpticalMicrolithographyXII ,L.V.denHove,Ed.,vol.3679,InternationalSocietyforOpticsandPhotonics.SPIE,1999,pp.228–238.[Online].Available: https://doi.org/10.1117/12.354336 [74] J.Croon,G.Storms,S.Winkelmeier,I.Pollentier,M.Er-cken,S.Decoutere,W.Sansen,andH.Maes,“Lineedgeroughness:characterization,modelingandimpactondevicebehavior,”in Digest.InternationalElectronDevicesMeeting, ,2002,pp.307–310. [75] V.Moroz,M.Choi,andX.-W.Lin,“Systematicstudyoftheimpactofcurvedactiveandpolycontoursontransistorperformance,”in DesignforManufacturabilitythroughDesign-ProcessIntegrationIII ,V.K.SinghandM.L.Rieger,Eds.,vol.7275,InternationalSocietyforOpticsandPhotonics.SPIE,2009,p.72751B.[Online].Available: https://doi.org/10.1117/12.814369 [76] Y.Ban,Y.Ma,H.J.Levinson,Y.Deng,J.Kye,andD.Z.Pan,“Modelingandcharacterizationofcontact-edgeroughnessforminimizingdesignand manufacturingvariationsin32-nmnodestandardcell,”in DesignforManufacturabilitythroughDesign-ProcessIntegrationIV ,M.L.RiegerandJ.Thiele,Eds.,vol.7641,InternationalSocietyforOpticsandPhotonics.SPIE,2010,p.76410D.[Online].Available: https://doi.org/10.1117/12.846654 [77] C.Wang,R.L.Jones,E.K.Lin,W.liWu,J.S.Villarrubia,K.-W.Choi,J.S.Clarke,B.J.Rice,M.Leeson,J.Roberts,R.Bristol,andB.Bunday,“Lineedgeroughnesscharacterizationofsub-50nmstructuresusingCD-SAXS:round-robinbenchmarkresults,”in Metrology,Inspection,andProcessControlforMicrolithographyXXI ,C.N.Archie,Ed.,vol.6518,InternationalSocietyforOpticsandPhotonics.SPIE,2007,p.65181O.[Online].Available: https://doi.org/10.1117/12.725380 [78] T.Fujiwara,T.Toki,D.Tanaka,M.Sato,J.Kosugi,R.Tanaka,N.Sakasai,T.Ohashi,R.Nakasone,andA.Tokui,“ProcesswindowcontrolusingCDUmaster,”in OpticalMicrolithographyXXV ,W.Conley,Ed.,vol.8326,InternationalSocietyforOpticsandPhotonics.SPIE,2012,p.83260Q.[Online].Available: https://doi.org/10.1117/12.916227 [79] P.A.Premkumar,A.Delabie,L.N.J.Rodriguez,A.Moussa,andC.Adelmann,“Roughnessevolutionduringtheatomiclayerdepositionofmetaloxides,” JournalofVacuumScience&TechnologyA ,vol.31,no.6,p.061501,072013.[Online].Available: https://doi.org/10.1116/1.4812707 [80] A.V.Novak,V.R.Novak,andD.I.Smirnov,“Evolutionofsurfacemorphologyduringthegrowthofamorphousandpolycrystallinesiliconfilms,” JournalofSurfaceInvestigation:X-ray,SynchrotronandNeutronTechniques ,vol.11,no.5,pp.1014–1021,2017.[Online].Available: https://link.springer.com/article/10.1134/S1027451017050317 [81] S.Assali,A.Attiaoui,S.Mukherjee,J.Nicolas,andO.Moutanabbir,“Teoslayersforlowtemperatureprocessingofgroupivoptoelectronicdevices,” JournalofVacuumScience&TechnologyB ,vol.36,no.6,p.061204,102018.[Online].Available: https://doi.org/10.1116/1.5047909 [82] T.P.Xiao,B.Feinberg,C.H.Bennett,V.Prabhakar,P.Saxena,V.Agrawal,S.Agarwal,andM.J.Marinella,“Ontheaccuracyofanalogneuralnetworkinferenceaccelerators,” IEEECircuitsandSystemsMagazine ,vol.22,no.4,pp.26–48,2022. [83] S.-Y.Wang,H.-T.Lue,P.-Y.Du,C.-W.Liao,E.-K.Lai,S.-C.Lai,L.-W.Yang,T.Yang,K.-C.Chen,J.Gong,K.-Y.Hsieh,R.Liu,andC.-Y.Lu,“Reliabilityandprocess-ingeffectsofbandgap-engineeredsonos(be-sonos)flashmemoryandstudyofthegate-stackscalingcapability,” IEEETransactionsonDeviceandMaterialsReliability ,vol.8,no.2,pp.416–425,2008. [84] B.J.Hosticka,“Dynamiccmosamplifiers,” IEEEJour-nalofSolid-StateCircuits ,vol.SC-15,no.5,pp.887– 894,October1980. [85] M.S.Akter,K.A.A.Makinwa,andK.Bult,“Acapac-itivelydegenerated100-dblinear20–150ms/sdynamicamplifier,” IEEEJournalofSolid-StateCircuits ,vol.53,no.4,pp.1115–1126,2018.